step_spline_b() 創建創建 b-spline 函數的配方步驟的規範。
用法
step_spline_b(
recipe,
...,
role = "predictor",
trained = FALSE,
deg_free = 10,
degree = 3,
complete_set = FALSE,
options = NULL,
keep_original_cols = FALSE,
results = NULL,
skip = FALSE,
id = rand_id("spline_b")
)參數
- recipe
-
一個菜譜對象。該步驟將添加到此配方的操作序列中。
- ...
-
一個或多個選擇器函數用於為此步驟選擇變量。有關更多詳細信息,請參閱
selections()。 - role
-
對於此步驟創建的模型項,應為其分配什麽分析角色?默認情況下,此步驟根據原始變量創建的新列將用作模型中的預測變量。
- trained
-
指示預處理數量是否已估計的邏輯。
- deg_free
-
b-spline 的自由度。隨著 b-spline 自由度的增加,可以生成更靈活和複雜的曲線。
- degree
-
指定分段多項式次數的非負整數。三次樣條的默認值為 3。分段常數基函數允許零度。
- complete_set
-
如果
TRUE,將返回完整的基礎矩陣。否則,第一個基礎將從輸出中排除。這映射到intercept相應函數的參數樣條2包並具有相同的默認值。 - options
-
splines2::bSpline()的選項列表,不應包括x、df、degree或intercept。 - keep_original_cols
-
將原始變量保留在輸出中的邏輯。默認為
FALSE。 - results
-
訓練步驟後創建的對象列表。
- skip
-
一個合乎邏輯的。當
bake()烘焙食譜時是否應該跳過此步驟?雖然所有操作都是在prep()運行時烘焙的,但某些操作可能無法對新數據進行(例如處理結果變量)。使用skip = TRUE時應小心,因為它可能會影響後續操作的計算。 - id
-
該步驟特有的字符串,用於標識它。
細節
樣條變換采用數字列並創建多個特征,當在模型中使用這些特征時,可以估計列和某些結果之間的非線性趨勢。自由度決定了向數據添加多少新特征。
如果所選列的樣條擴展失敗,該步驟將刪除該列的結果(但將保留原始數據)。使用tidy() 方法確定使用了哪些列。
整理
當您tidy()此步驟時,將返回帶有列terms(將受影響的列)的tibble。
例子
library(tidyr)
library(dplyr)
library(ggplot2)
data(ames, package = "modeldata")
spline_rec <- recipe(Sale_Price ~ Longitude, data = ames) %>%
step_spline_b(Longitude, deg_free = 6, keep_original_cols = TRUE) %>%
prep()
tidy(spline_rec, number = 1)
#> # A tibble: 1 × 2
#> terms id
#> <chr> <chr>
#> 1 Longitude spline_b_FXUpF
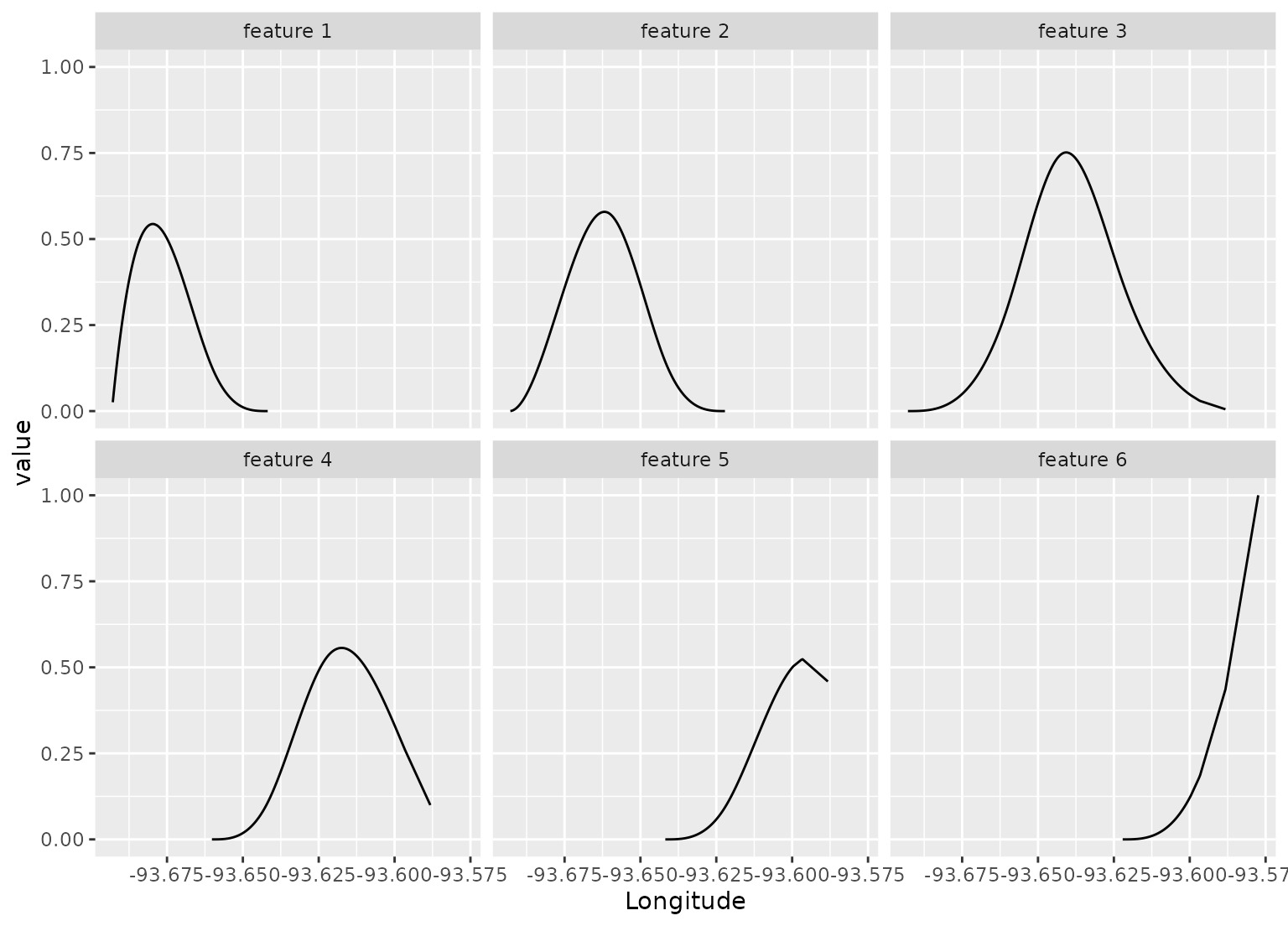
# Show where each feature is active
spline_rec %>%
bake(new_data = NULL,-Sale_Price) %>%
pivot_longer(c(starts_with("Longitude_")), names_to = "feature", values_to = "value") %>%
mutate(feature = gsub("Longitude_", "feature ", feature)) %>%
filter(value > 0) %>%
ggplot(aes(x = Longitude, y = value)) +
geom_line() +
facet_wrap(~ feature)
相關用法
- R recipes step_spline_nonnegative 非負樣條
- R recipes step_spline_natural 自然樣條
- R recipes step_spline_convex 凸樣條
- R recipes step_spline_monotone 單調樣條
- R recipes step_spatialsign 空間符號預處理
- R recipes step_select 使用 dplyr 選擇變量
- R recipes step_shuffle 隨機排列變量
- R recipes step_scale 縮放數值數據
- R recipes step_string2factor 將字符串轉換為因子
- R recipes step_sample 使用 dplyr 的示例行
- R recipes step_slice 使用 dplyr 按位置過濾行
- R recipes step_sqrt 平方根變換
- R recipes step_unknown 將缺失的類別分配給“未知”
- R recipes step_relu 應用(平滑)修正線性變換
- R recipes step_poly_bernstein 廣義伯恩斯坦多項式基
- R recipes step_impute_knn 通過 k 最近鄰進行插補
- R recipes step_impute_mean 使用平均值估算數值數據
- R recipes step_inverse 逆變換
- R recipes step_pls 偏最小二乘特征提取
- R recipes step_ratio 比率變量創建
- R recipes step_geodist 兩個地點之間的距離
- R recipes step_nzv 近零方差濾波器
- R recipes step_nnmf 非負矩陣分解信號提取
- R recipes step_normalize 中心和比例數值數據
- R recipes step_depth 數據深度
注:本文由純淨天空篩選整理自Max Kuhn等大神的英文原創作品 Basis Splines。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。