step_bsmote() 創建配方步驟的規範,該步驟使用類之間邊界區域中這些案例的最近鄰居來生成少數類的新示例。
用法
step_bsmote(
recipe,
...,
role = NA,
trained = FALSE,
column = NULL,
over_ratio = 1,
neighbors = 5,
all_neighbors = FALSE,
skip = TRUE,
seed = sample.int(10^5, 1),
id = rand_id("bsmote")
)參數
- recipe
-
一個菜譜對象。該步驟將添加到此配方的操作序列中。
- ...
-
一個或多個選擇器函數用於選擇使用哪個變量對數據進行采樣。有關更多詳細信息,請參閱
selections()。選擇應產生單因子變量。對於tidy方法,當前未使用這些。 - role
-
由於沒有創建新變量,因此此步驟未使用。
- trained
-
指示預處理數量是否已估計的邏輯。
- column
-
將由
...選擇器(最終)填充的變量名稱的字符串。 - over_ratio
-
多數頻率與少數頻率之比的數值。默認值 (1) 表示對所有其他級別進行采樣,使其具有與最常出現的級別相同的頻率。值為 0.5 意味著少數級別的行數(最多)(大約)是多數級別的一半。
- neighbors
-
一個整數。用於生成少數類新示例的最近鄰居的數量。
- all_neighbors
-
兩個borderline-SMOTE方法的類型。默認為 FALSE。查看具體信息。
- skip
-
一個合乎邏輯的。當
bake()烘焙食譜時是否應該跳過此步驟?雖然所有操作都是在prep()運行時烘焙的,但某些操作可能無法對新數據進行(例如處理結果變量)。使用skip = TRUE時應小心,因為它可能會影響後續操作的計算。 - seed
-
當 smote-ing 時將用作種子的整數。
- id
-
該步驟特有的字符串,用於標識它。
細節
此方法的用法方式與 step_smote() 相同,期望不是在少數類的每個點周圍生成點,而是首先將每個點分類到框 "danger" 和 "not" 中。對於每個點,計算 k 個最近鄰點。如果所有鄰居都來自不同的類別,則它會被標記為噪聲並放入 "not" 框中。如果超過一半的鄰居來自不同階層,則被標記為“危險”。
如果all_neighbors = FALSE,則將在其自己的類中的最近鄰居之間生成點。如果all_neighbors = TRUE,則將在任何最近的鄰居之間生成點。請參閱可視化示例。
參數neighbors控製新示例的創建方式。對於每個當前存在的少數類示例,將創建 X 個新示例(這由參數 over_ratio 控製,如上所述)。這些示例將通過使用來自少數類每個示例的 neighbors 最近鄰居的信息來生成。參數neighbors控製使用多少個鄰居。
數據中的所有列均由 juice() 和 bake() 采樣並返回。
此步驟中使用的所有列都必須是數字且沒有丟失數據。
在建模中使用時,用戶應強烈考慮使用選項skip = TRUE,以便不在訓練集之外進行額外采樣。
整理
當您tidy()此步驟時,將返回包含列terms(選擇的選擇器或變量)的tibble。
調整參數
這一步有3個調整參數:
-
over_ratio:過采樣率(類型:double,默認值:1) -
neighbors: # 最近鄰居(類型:整數,默認值:5) -
all_neighbors:所有鄰居(類型:邏輯,默認值:FALSE)
也可以看看
bsmote() 直接實現
過采樣的其他步驟:step_adasyn()、step_rose()、step_smotenc()、step_smote()、step_upsample()
例子
library(recipes)
library(modeldata)
data(hpc_data)
hpc_data0 <- hpc_data %>%
select(-protocol, -day)
orig <- count(hpc_data0, class, name = "orig")
orig
#> # A tibble: 4 × 2
#> class orig
#> <fct> <int>
#> 1 VF 2211
#> 2 F 1347
#> 3 M 514
#> 4 L 259
up_rec <- recipe(class ~ ., data = hpc_data0) %>%
# Bring the minority levels up to about 1000 each
# 1000/2211 is approx 0.4523
step_bsmote(class, over_ratio = 0.4523) %>%
prep()
training <- up_rec %>%
bake(new_data = NULL) %>%
count(class, name = "training")
training
#> # A tibble: 4 × 2
#> class training
#> <fct> <int>
#> 1 VF 2211
#> 2 F 1347
#> 3 M 1000
#> 4 L 1000
# Since `skip` defaults to TRUE, baking the step has no effect
baked <- up_rec %>%
bake(new_data = hpc_data0) %>%
count(class, name = "baked")
baked
#> # A tibble: 4 × 2
#> class baked
#> <fct> <int>
#> 1 VF 2211
#> 2 F 1347
#> 3 M 514
#> 4 L 259
# Note that if the original data contained more rows than the
# target n (= ratio * majority_n), the data are left alone:
orig %>%
left_join(training, by = "class") %>%
left_join(baked, by = "class")
#> # A tibble: 4 × 4
#> class orig training baked
#> <fct> <int> <int> <int>
#> 1 VF 2211 2211 2211
#> 2 F 1347 1347 1347
#> 3 M 514 1000 514
#> 4 L 259 1000 259
library(ggplot2)
ggplot(circle_example, aes(x, y, color = class)) +
geom_point() +
labs(title = "Without SMOTE")
 recipe(class ~ x + y, data = circle_example) %>%
step_bsmote(class, all_neighbors = FALSE) %>%
prep() %>%
bake(new_data = NULL) %>%
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With borderline-SMOTE, all_neighbors = FALSE")
recipe(class ~ x + y, data = circle_example) %>%
step_bsmote(class, all_neighbors = FALSE) %>%
prep() %>%
bake(new_data = NULL) %>%
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With borderline-SMOTE, all_neighbors = FALSE")
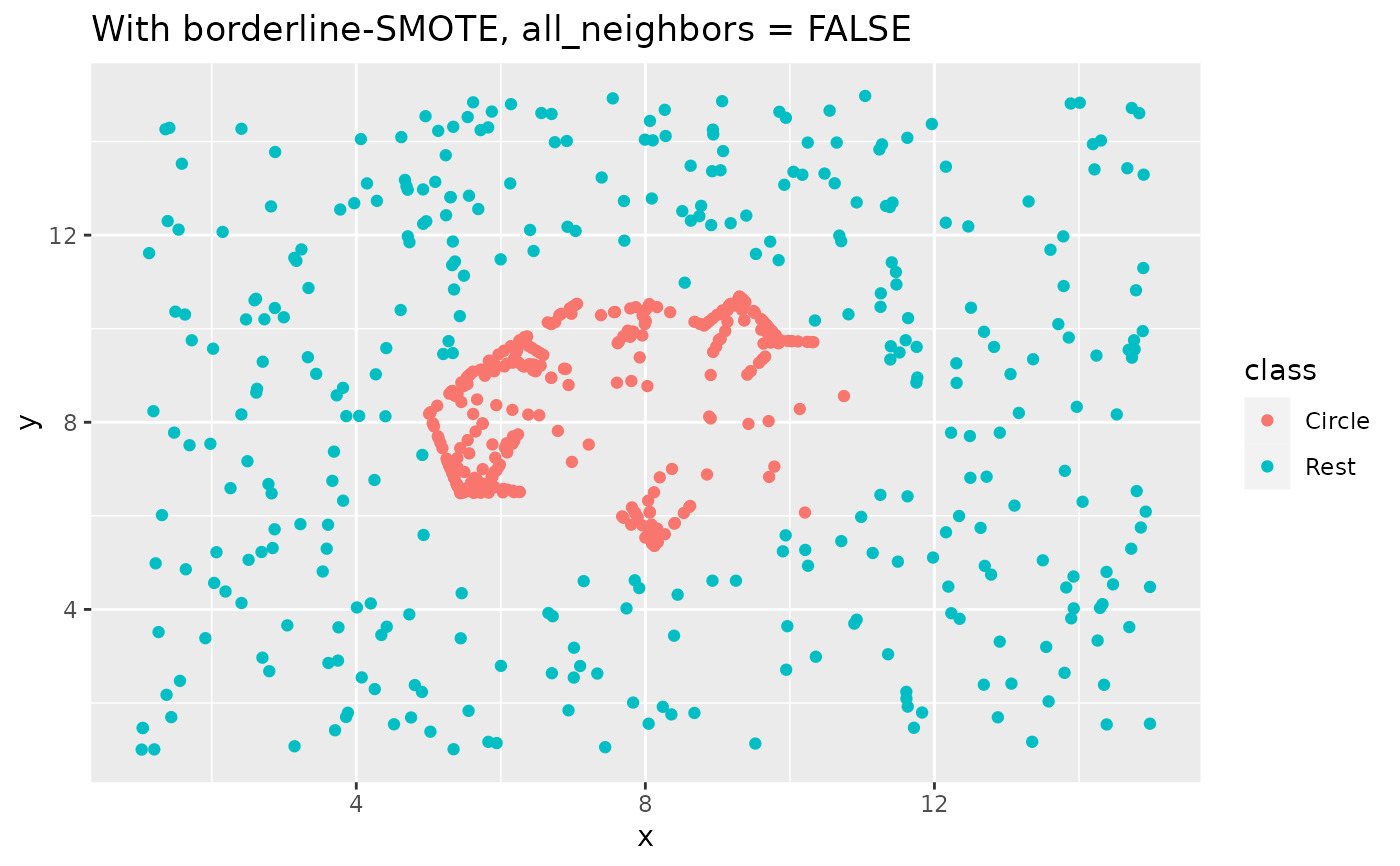 recipe(class ~ x + y, data = circle_example) %>%
step_bsmote(class, all_neighbors = TRUE) %>%
prep() %>%
bake(new_data = NULL) %>%
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With borderline-SMOTE, all_neighbors = TRUE")
recipe(class ~ x + y, data = circle_example) %>%
step_bsmote(class, all_neighbors = TRUE) %>%
prep() %>%
bake(new_data = NULL) %>%
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With borderline-SMOTE, all_neighbors = TRUE")
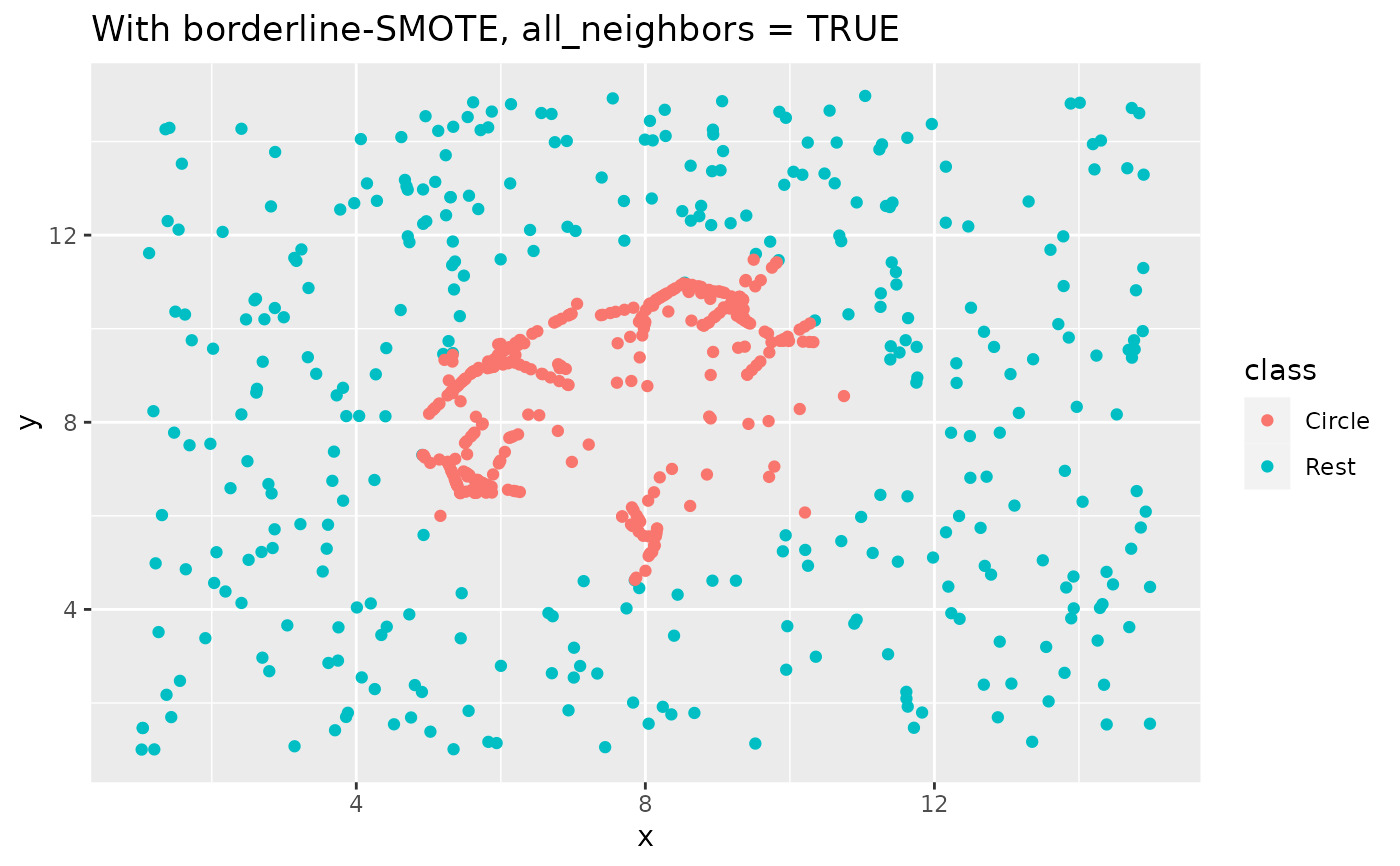
相關用法
- R themis step_smote 應用SMOTE算法
- R themis step_smotenc 應用 SMOTENC 算法
- R themis step_downsample 基於因子變量對數據集進行下采樣
- R themis step_tomek 刪除 Tomek 的鏈接
- R themis step_rose 應用ROSE算法
- R themis step_upsample 基於因子變量對數據集進行上采樣
- R themis step_nearmiss 刪除其他類附近的點
- R themis step_adasyn 應用自適應合成算法
- R themis smotenc SMOTENC算法
- R themis smote SMOTE算法
- R themis tomek 刪除 Tomek 的鏈接
- R themis bsmote 邊界-SMOTE算法
- R themis nearmiss 刪除其他類附近的點
- R themis adasyn 自適應合成算法
- R update_PACKAGES 更新現有的 PACKAGES 文件
- R textrecipes tokenlist 創建令牌對象
- R print.via.format 打印實用程序
- R tibble tibble 構建 DataFrame 架
- R tidyr separate_rows 將折疊的列分成多行
- R textrecipes step_lemma 標記變量的詞形還原
- R textrecipes show_tokens 顯示配方的令牌輸出
- R tidyr extract 使用正則表達式組將字符列提取為多列
- R prepare_Rd 準備用於渲染的解析 Rd 對象
- R tidyr chop 砍伐和砍伐
- R tidyr pivot_longer_spec 使用規範將數據從寬轉為長
注:本文由純淨天空篩選整理自等大神的英文原創作品 Apply borderline-SMOTE Algorithm。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。