Python是進行數據分析的一種出色語言,主要是因為以數據為中心的Python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas endswith()是在係列或 DataFrame 中搜索和過濾文本數據的另一種方法。此方法類似於Python的endswith()方法,但參數不同,並且僅適用於Pandas對象。因此,.str必須在每次調用此方法之前加上前綴,以便編譯器知道它與默認函數不同。
用法:Series.str.endswith(pat, na=nan)
參數:
pat:要搜索的字符串。不接受正則表達式
na:用於設置序列中的值為NULL時應顯示的內容。
返回類型:布爾序列,為True,其中值的末尾帶有傳遞的字符串。
要下載代碼中使用的CSV,請點擊此處。
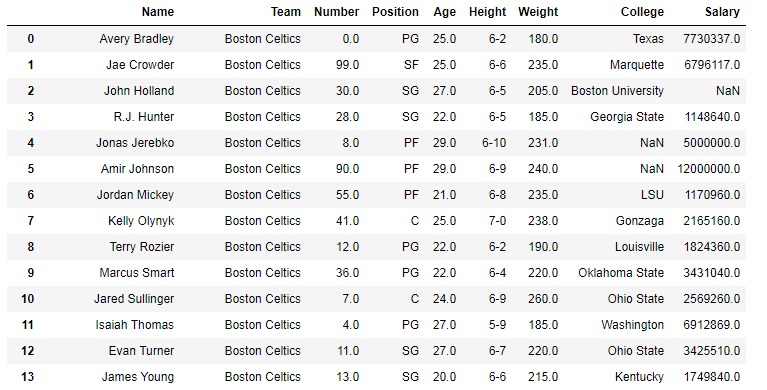
在以下示例中,使用的 DataFrame 包含一些NBA球員的數據。下麵是任何操作之前的數據幀圖像。
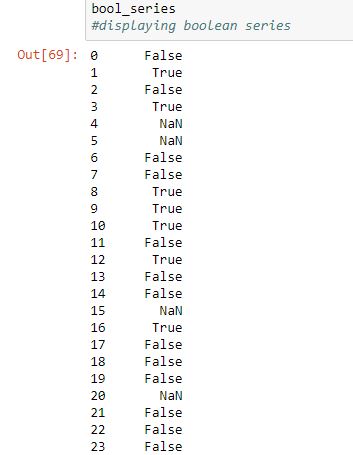
範例1:返回布爾係列
在此示例中,使用字符串來檢查元素是否在字符串末尾具有“e”的College列str.endswith()函數。返回一個布爾序列,該序列在字符串末尾具有“e”的索引位置處為真。str.lower() 因為在任何情況下數據都可以,所以在endswith()之前調用此方法。
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# String to be searched in end of string
search ="e"
# boolean series returned with False at place of NaN
bool_series = data["College"].str.lower().str.endswith(search)
# displaying boolean series
bool_series輸出:
如輸出圖像中所示,布爾係列在“ College”列最後具有“e”的索引位置處具有True。也可以通過查看原始數據幀的圖像進行比較。
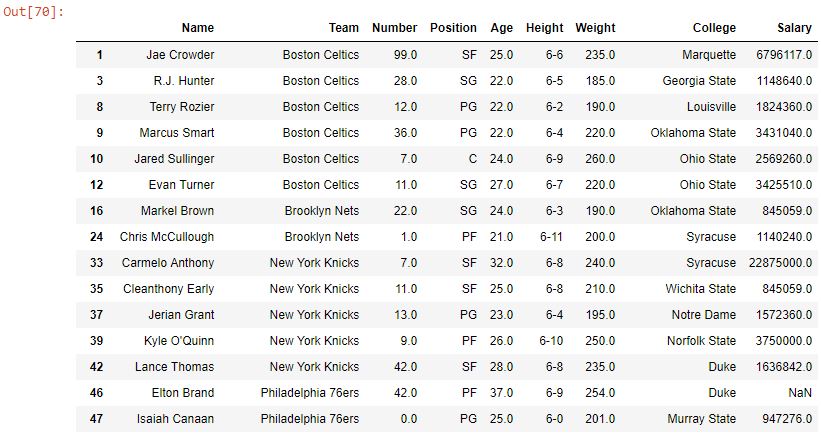
範例2:處理NULL值
數據分析中最重要的部分是處理Null值。從上麵的輸出圖像中可以看出,布爾序列在“學院”列中的值為空或NaN的地方都具有NaN。如果將此布爾係列傳遞到數據幀中,則會產生錯誤。因此,需要使用na參數來處理NaN值。也可以將其設置為字符串,但是由於布爾序列用於傳遞和返回各自的值,因此應僅將其設置為布爾值。在此示例中,na Parameter設置為False。因此,無論“學院”列的值為Null,Bool係列將存儲False而不是NaN。之後,該係列將再次傳遞到 DataFrame 以僅顯示True值。
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# String to be searched in end of string
search ="e"
# boolean series returned with False at place of NaN
bool_series = data["College"].str.lower().str.endswith(search, na = False)
# displaying filtered dataframe
data[bool_series]輸出:
如輸出圖像中所示,數據幀具有在College列的字符串末尾具有“e”的行。由於na參數設置為False,因此不會顯示NaN值。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Timestamp.tz用法及代碼示例
- Python Pandas Series.str.contains()用法及代碼示例
- Python Pandas dataframe.std()用法及代碼示例
- Python Pandas Timestamp.dst用法及代碼示例
- Python Pandas dataframe.sem()用法及代碼示例
- Python Pandas DataFrame.ix[ ]用法及代碼示例
- Python Pandas.Categorical()用法及代碼示例
- Python Pandas.apply()用法及代碼示例
- Python Pandas TimedeltaIndex.contains用法及代碼示例
- Python Pandas Timestamp.now用法及代碼示例
- Python Pandas Series.str.pad()用法及代碼示例
- Python Pandas Series.take()用法及代碼示例
- Python Pandas dataframe.all()用法及代碼示例
- Python Pandas series.str.get()用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Series.str.endswith()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。