下麵是章節頻繁模式挖掘的內容(其他內容參見全文目錄)
頻繁項集挖掘是通常是大規模數據分析的第一步,多年以來它都是數據挖掘領域的活躍研究主題。建議用戶參考維基百科的association rule learning 了解更多信息。MLlib支持了一個並行的FP-growth,FP-growth是很受歡迎的頻繁項集挖掘算法。
FP-growth
FP-growth算法在論文Han et al., Mining frequent patterns without candidate generation 中有詳細論述,其中FP指的是頻繁模式(frequent pattern)。給定一個事務數據集,FP-growth算法的第一步是計算項的頻度並標記頻繁項。跟Apriori這類挖掘頻繁項集算法不同的是,FP-growth的第二步使用了一個FP-tree結構來編碼事務。第二部之後,頻繁項集可以直接從FP-tree中提取。在MLlib中,我們實現了一個FP-growth的並行版本(PFP),具體方法參見論文Li et al., PFP: Parallel FP-growth for query recommendation。
MLlib中FP-growth實現的參數:
minSupport: 最小支持度。用浮點數表示比例。例如某項在5個事務中出現3次,其支持度為3/5=0.6。numPartitions: 計算的分區數量。
示例(scala)
FPGrowth 實現了 FP-growth 算法. 其輸入是事務RDD, 每個事務是一個可遍曆的項集。 調用 FPGrowth.run 返回FPGrowthModel ,它存儲的是頻繁項集以及對應頻度。
import org.apache.spark.rdd.RDD
import org.apache.spark.mllib.fpm.{FPGrowth, FPGrowthModel}
val transactions: RDD[Array[String]] = ...
val fpg = new FPGrowth()
.setMinSupport(0.2)
.setNumPartitions(10)
val model = fpg.run(transactions)
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq)
}
補充:
1. Apriori求頻繁項集的基本原理(有點像數學歸納法):
- 首先找到頻繁1項集(大於支持度的單項)
- 由k項集生成k+1項集,生成的方式是:將k項集中的元素兩兩組合(求並集),大於支持度的作為k+1項集。
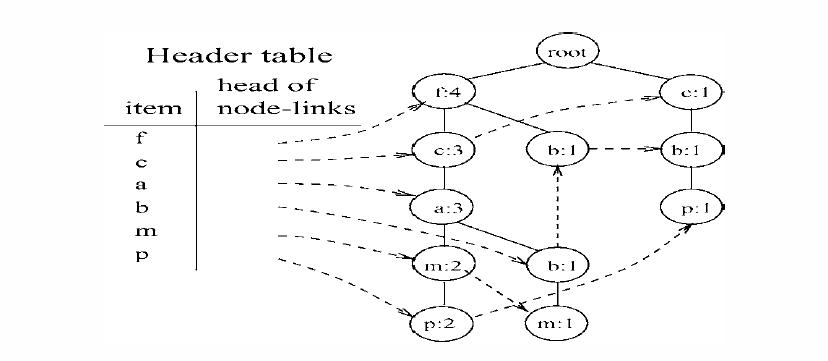
2. FP-Growth算法求頻繁項集的基本原理:
- 首先對單項按頻度排序,去掉小於支持度的項
- 對每一條記錄,對項按1中計算的頻度排序。
- 將記錄依次插入到FP-Tree(一個前綴共享樹)
- 為相同的節點增加頭表結構(見下圖)。
- 找到每個頭表項的條件模式基(CPB),保留後綴,將CPB作為新的數據集,回到開始遞歸處理(樹節點為空是,輸出頭表項+後綴)
參考:
[1] http://zh.wikipedia.org/wiki/%E5%85%B3%E8%81%94%E5%BC%8F%E8%A7%84%E5%88%99
[2] http://www.cnblogs.com/zhangchaoyang/articles/2198946.html
[3] http://hi.baidu.com/nefzpohtpndhovr/item/9d5c371ba2dbdc0ed1d66dca