本文简要介绍 python 语言中 arcgis.geoanalytics.analyze_patterns.forest 的用法。
用法:
arcgis.geoanalytics.analyze_patterns.forest(input_layer, var_prediction, var_explanatory, trees, max_tree_depth=None, random_vars=None, sample_size=100, min_leaf_size=None, prediction_type='train', features_to_predict=None, validation=10, importance_tbl=False, exp_var_matching=None, output_name=None, gis=None, context=None, future=False, return_tuple=False)返回:
如果
return_tuple设置为“True”,则结果元组具有以下键:output:FeatureLayeroutput_predicted:FeatureLayercoefficient_table:Tableprocess_info:列表
否则,
FeatureLayer
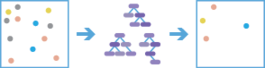
‘forest’ 方法是基于森林的分类和回归任务,它使用 Leo Breiman 的随机森林算法(一种有监督的机器学习方法)的改编创建模型并生成预测。可以对分类变量(分类)和连续变量(回归)执行预测。解释变量可以采用训练特征属性表中字段的形式。除了基于训练数据验证模型性能之外,还可以对另一个特征数据集进行预测。
以下是示例:
Given data on occurrence of seagrass, as well as a number of environmental explanatory variables represented as both attributes which has been enriched using a multi-variable grid to calculate distances to factories upstream and major ports, future seagrass occurrence can be predicted based on future projections for those same environmental explanatory variables.
Suppose you have crop yield data at hundreds of farms across the country along with other attributes at each of those farms (number of employees, acreage, and so on). Using these pieces of data, you can provide a set of features representing farms where you don’t have crop yield (but you do have all of the other variables), and make a prediction about crop yield.
Housing values can be predicted based on the prices of houses that have been sold in the current year. The sale price of homes sold along with information about the number of bedrooms, distance to schools, proximity to major highways, average income, and crime counts can be used to predict sale prices of similar homes.
注意:
ArcGIS Enterprise 10.7 中提供了基于森林的分类和回归。
Parameter
Description
input_layer
必需的层。将用于训练数据集的特征。该层必须包括表示要预测的变量和解释变量的字段。请参阅特征输入。
var_prediction
必需的字典。
input_layer参数中的变量包含用于训练模型的值,以及一个表示它是否为分类的布尔值。此字段包含将用于在未知位置进行预测的变量的已知(训练)值。语法:
{"fieldName":"<field name>", "categorical":bool}var_explanatory
必填清单。表示解释变量的字段列表和表示字段是否为分类的布尔值。解释变量有助于预测
var_prediction参数的值或类别。对表示类或类别(例如土地覆盖或存在或不存在)的任何变量使用分类参数。对于任何代表类或类别(例如土地覆盖或存在或不存在)的变量,将变量指定为“True”,如果变量是连续的,则将其指定为“False”。用法:
[{"fieldName":"<field name>", "categorical":bool},...]trees
必需的整数。在森林模型中创建的树的数量。更多的树通常会导致更准确的模型预测,但模型会花费更长的时间来计算。
max_tree_depth
可选整数。将沿树进行的最大拆分数。使用较大的最大深度,将创建更多的分割,这可能会增加模型过度拟合的机会。默认值是数据驱动的,取决于创建的树数和包含的变量数。
max_tree_depth必须为正且小于或等于 30。random_vars
可选整数。指定用于创建每个决策树的解释变量的数量。森林中的每个决策树都是使用指定的解释变量的随机子集创建的。增加每个决策树中使用的变量数量将增加过度拟合模型的机会,尤其是在存在一个或几个主要变量的情况下。如果您的 variablePredict 是数字,则通常的做法是使用解释变量总数(字段、距离和栅格组合)的平方根,或者将解释变量(字段、距离和栅格组合)的总数除以 3,如果
var_prediction是分类的。sample_size
可选整数。指定用于每个决策树的
input_layer的百分比。每棵树的样本都是从指定数据的two-thirds 中随机抽取的。默认值为 100% 的数据。
min_leaf_size
可选整数。保持叶子(即树上没有进一步分裂的终端节点)所需的最小观察次数。对于非常大的数据,增加这些数字将减少工具的运行时间。
回归的默认最小值为 5,分类的默认最小值为 1。
prediction_type
可选字符串。指定工具的操作模式。可以运行该工具来训练模型以仅评估性能,或训练模型并预测特征。预测类型如下:
Train- A model will be trained, but no predictions will be generated. Use this option to assess the accuracy of your model before generating predictions. This option will output model diagnostics in the messages window and a chart of variable importance.TrainAndPredict- Predictions or classifications will be generated for features. Explanatory variables must be provided for both the training features and the features to be predicted. The output of this option will be a feature service, model diagnostics, and an optional table of variable importance.
默认值为“训练”。
features_to_predict(如果使用
TrainAndPredict则需要)可选层。表示将进行预测的位置的要素图层。此层必须包含与
input_layer中使用的字段相对应的解释变量字段。此参数仅在prediction_type为TrainAndPredict时使用并且在这种情况下是必需的。请参阅特征输入。validation
可选整数。指定要保留作为验证测试数据集的 inFeatures 百分比(10% 到 50% 之间)。该模型将在没有此随机数据子集的情况下进行训练,并将这些特征的观察值与预测值进行比较。
默认值为 10%。
importance_tbl
可选的布尔值。指定是否将生成一个输出表,其中包含说明创建的模型中使用的每个解释变量的重要性的信息。
exp_var_matching
可选的字典列表。表示解释变量的字段列表和表示字段是否为分类的布尔值。解释变量有助于预测 variable_predict 的值或类别。对表示类或类别(例如土地覆盖或存在或不存在)的任何变量使用分类参数。对于任何代表类或类别(例如土地覆盖或存在或不存在)的变量,将变量指定为“True”,如果变量是连续的,则将其指定为“False”。
用法:
[{"fieldName":"<explanatory field name>", "categorical":bool}]fieldname is the name of the field in the
input_layerused to predict thevar_prediction.categorical is one of: ‘True’ or ‘False’. A string field should always be ‘True’, and a continue value should always be set as ‘False’.
output_name
可选字符串。该任务将创建结果的要素服务。您定义服务的名称。
gis
可选
GIS。运行该工具的 GIS。如果未指定,则使用活动 GIS。context
可选字典。 context 参数包含影响任务执行的其他设置。对于此任务,有四个设置:
extent- A bounding box that defines the analysis area. Only those features that intersect the bounding box will be analyzed.processSR- The features will be projected into this coordinate system for analysis.outSR- The features will be projected into this coordinate system after the analysis to be saved. The output spatial reference for the spatiotemporal big data store is always WGS84.dataStore- Results will be saved to the specified data store. For ArcGIS Enterprise, the default is the spatiotemporal big data store.
future
可选的布尔值。如果为“真”,则返回 GPJob 而不是结果。可以查询GPJob 的执行状态。
默认值为“假”。
return_tuple
可选的布尔值。如果为“True”,则返回具有多个输出键的命名元组。
默认值为“假”。
例子:
# Usage Example: To predict the number of 911 calls in each block group. predicted_result = forest(input_layer=call_lyr, var_prediction={"fieldName":"Calls", "categorical":False}, var_explanatory=[{"fieldName":"Pop", "categorical":False}, {"fieldName":"Unemployed", "categorical":False}, {"fieldName":"AlcoholX", "categorical":False}, {"fieldName":"UnEmpRate", "categorical":False}, {"fieldName":"MedAge00", "categorical":False}], trees=50, max_tree_depth=10, random_vars=3, sample_size=100, min_leaf_size=5, prediction_type='TrainAndPredict', validation=10, importance_tbl=True, output_name='train and predict number of 911 calls')
相关用法
- Python ArcGIS find_centroids用法及代码示例
- Python ArcGIS from_geo_coordinate_string用法及代码示例
- Python ArcGIS find_point_clusters用法及代码示例
- Python ArcGIS flow_direction用法及代码示例
- Python ArcGIS float_divide用法及代码示例
- Python ArcGIS find_existing_locations用法及代码示例
- Python ArcGIS find_nearest用法及代码示例
- Python ArcGIS floor_divide用法及代码示例
- Python ArcGIS find_hot_spots用法及代码示例
- Python ArcGIS find_outliers用法及代码示例
- Python ArcGIS find_argument_statistics用法及代码示例
- Python ArcGIS find_similar_locations用法及代码示例
- Python ArcGIS power用法及代码示例
- Python ArcGIS APIKeyManager.get用法及代码示例
- Python ArcGIS KnowledgeGraph.named_object_type_delete用法及代码示例
- Python ArcGIS ContentManager.unshare_items用法及代码示例
- Python ArcGIS ImageryLayer.thumbnail用法及代码示例
- Python ArcGIS FormFieldElement用法及代码示例
- Python ArcGIS Geometry.true_centroid用法及代码示例
- Python ArcGIS Site.delete用法及代码示例
- Python ArcGIS GeoAccessor.bbox用法及代码示例
- Python arcgis.apps.hub.Initiative.update用法及代码示例
- Python ArcGIS generate_service_areas用法及代码示例
- Python ArcGIS build_overview用法及代码示例
- Python ArcGIS RunInterval用法及代码示例
注:本文由纯净天空筛选整理自arcgis.com大神的英文原创作品 arcgis.geoanalytics.analyze_patterns.forest。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。