本文简单介绍一种最基本的矩阵乘法的实现方法。
设有矩阵A(M×N)和矩阵B(N×K),令C=A*B, 那么矩阵C(M×K)的元素为:
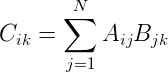 其中Cik是C的第i行第k列的元素;Aij是A的第i行第j列的元素;Bjk是B的第j行第k列的元素。
其中Cik是C的第i行第k列的元素;Aij是A的第i行第j列的元素;Bjk是B的第j行第k列的元素。
注意:如果A和B可乘,那么A的列数等于B的行数。
对于小数据量下的矩阵运算,可以直接在单机内存中根据上述公式直接计算得到。对于大数据下的矩阵运算,我们可以把上述公式搬到hadoop上来实现。
通常在Hadoop上通过MapReduce 实现矩阵运算需要两轮:第一步计算A和B对应的元素两两乘积(Aij * Bjk);第二步,对所有的j, 将上一步得到的Aij*Bjk的乘积求和。具体说明如下:
- 第一轮
- Map: 将矩阵A,B的元素分别表示成键值对的形式,其中A的元素Aij表示为j => (A, i, Aij), B的元素Bjk表示为j => (B, k, Bjk)。
- Reduce: 对于每个键j, 将j对应的所有A中的元素和对应的所有B中的元素两两相乘(Aij*Bjk),输出i,k => Aij * Bjk,其中i,k组合在一起作为输出的键值。
- 第二轮
- Map: 直接做cat操作(上一轮的i,k为key, 对应的乘积为value)
- Reduce: 将组合键i,k对应的所有value求和。输出i,k => sum即为结果矩阵的元素(第i行第k列)。
上述算法的时间负责度: 由于计算结果矩阵C的每个元素需要将矩阵A的整行和B的整列对应的元素相乘,其时间复杂度为O(N),而C总共有M*K个,所以总的时间复杂度为O(M*K*N),如果M=N=K,就是O(N3)。[注:目前最好的矩阵乘法时间负责度为O(N2.367),其中strassen的方法是O(Nlog7)≈O(N2.8074),他采用分治思想并将最后2×2小矩阵的计算时间从8次减少到7次]
上述两轮MapReduce的具体实现如下:
- 第一轮的hadoop streaming控制程序
#!/bin/bash #矩阵乘法, MR第一轮计算 if [ $# -ne 0 ] then echo "Usage: $0" exit 1 fi INPUT_DIR=/data/fuqingchuan/matrix/A4x4.txt,/data/fuqingchuan/matrix/B4x3.txt OUTPUT_DIR=/data/fuqingchuan/matrix/one/ STREAM_FILE="/home/hadoop/hadoop-2.3.0-cdh5.1.0/share/hadoop/tools/lib/hadoop-streaming-2.3.0-cdh5.1.0.jar" ${HADOOP_HOME}/bin/hadoop fs -rm -r ${OUTPUT_DIR} ${HADOOP_HOME}/bin/hadoop jar ${STREAM_FILE} \ -D mapreduce.job.name="matrix-one-fuqingchuan" \ -D mapreduce.job.reduces=100 \ -D mapreduce.job.priority=NORMAL \ -D mapreduce.job.map.capacity=100 \ -D mapreduce.job.reduce.capacity=100 \ -D mapreduce.job.reduce.slowstart.completedmaps=0.95 \ -D stream.num.map.output.key.fields=1 \ -D stream.memory.limit=1000 \ -D mapreduce.map.memory.mb=1000 \ -D mapreduce.reduce.memory.mb=1000 \ -D mapreduce.reduce.failures.maxpercent=1 \ -input ${INPUT_DIR} \ -output ${OUTPUT_DIR} \ -mapper "python mapper_one.py" \ -reducer "python reducer_one.py" \ -file ./mapper_one.py \ -file ./reducer_one.py exit 0 - 第一轮的mapper(以j作为Key):
#!/usr/bin/python #coding=utf8 #matrix multiplier : first round. #input: two matrix, A(mxn), B(nxk) #output: (j A i Aij) or (j B k Bjk) import sys; import logging as log; if __name__ == "__main__": for rawline in sys.stdin: line = rawline.rstrip(); if len(line) <= 0: continue; fields = line.split(" "); flen = len(fields); if flen < 3: log.warning("invalid input line:%s"%line.rstrip()); continue; name = fields[0]; if name != "A" and name != "B": log.warning("invalid matrix name:%s. It should be A|B."); continue; row = fields[1]; for idx in range(2, flen): value = fields[idx]; if name == "A": # Aij => j A i Aij i = row; j = idx - 2; print "%d\t%s\t%s\t%s"%(j, name, i, value); else: # Bjk => j B k Bjk j = row; k = idx - 2; print "%s\t%s\t%d\t%s"%(j, name, k, value); sys.exit(0); - 第一轮的reducer(计算乘积,并以i,k作为Key输出):
#!/usr/bin/python #coding=utf8 #matrix multiplier : first round. #input: a matrix[Aij -> ith row, jth col] #output: import sys; import logging as log; def output(listA, listB): for Aij in listA: for Bjk in listB: A_i = Aij[0]; A_j = Aij[1]; A_v = Aij[2]; B_j = Bjk[0]; B_k = Bjk[1]; B_v = Bjk[2]; if A_j != B_j: continue; print "%d,%d\t%d"%(A_i, B_k, A_v * B_v); if __name__ == "__main__": listA = []; listB = []; last_j = None; for rawline in sys.stdin: line = rawline.rstrip(); if len(line) <= 0: continue; fields = line.split("\t"); flen = len(fields); if flen != 4: log.warning("invalid input line:%s"%line.rstrip()); continue; j = int(fields[0]); name = fields[1]; value = int(fields[3]); if last_j == None or j == last_j: pass; else: output(listA, listB); listA = []; listB = []; if name == "A": i = int(fields[2]); listA.append((i, j, value)); else: #B k = int(fields[2]); listB.append((j, k, value)); last_j = j; if last_j != None: output(listA, listB); sys.exit(0); - 第二轮的hadoop streaming总控程序:
#!/bin/bash #矩阵乘法, MR第二轮计算 if [ $# -ne 0 ] then echo "Usage: $0" exit 1 fi INPUT_DIR=/data/fuqingchuan/matrix/one/ OUTPUT_DIR=/data/fuqingchuan/matrix/two/ STREAM_FILE="/home/hadoop/hadoop-2.3.0-cdh5.1.0/share/hadoop/tools/lib/hadoop-streaming-2.3.0-cdh5.1.0.jar" ${HADOOP_HOME}/bin/hadoop fs -rm -r ${OUTPUT_DIR} ${HADOOP_HOME}/bin/hadoop jar ${STREAM_FILE} \ -D mapreduce.job.name="matrix-two-fuqingchuan" \ -D mapreduce.job.reduces=100 \ -D mapreduce.job.priority=NORMAL \ -D mapreduce.job.map.capacity=100 \ -D mapreduce.job.reduce.capacity=100 \ -D mapreduce.job.reduce.slowstart.completedmaps=0.95 \ -D stream.num.map.output.key.fields=1 \ -D stream.memory.limit=1000 \ -D mapreduce.map.memory.mb=1000 \ -D mapreduce.reduce.memory.mb=1000 \ -D mapreduce.reduce.failures.maxpercent=1 \ -input ${INPUT_DIR} \ -output ${OUTPUT_DIR} \ -mapper "cat" \ -reducer "python reducer_two.py" \ -file ./reducer_two.py exit 0 - 第二轮mapper直接cat就可以了。
- 第二轮reducer(求和,以i,k作为Key输出):
#!/usr/bin/python #coding=utf8 #matrix multiplier : first round. #input: a matrix[Aij -> ith row, jth col] #output: import sys; import logging as log; def output(last_ik, sum): print "%s\t%d"%(last_ik, sum); if __name__ == "__main__": last_ik = None; sum = 0; for rawline in sys.stdin: line = rawline.rstrip(); if len(line) <= 0: continue; fields = line.split("\t"); flen = len(fields); if flen != 2: log.warning("invalid input line:%s"%line.rstrip()); continue; ik = fields[0]; value = int(fields[1]); if last_ik == None or ik == last_ik: sum += value; else: output(last_ik, sum); sum = value; last_ik = ik; if last_ik != None: output(last_ik, sum); sys.exit(0);