梯度提升入门
简化复杂的算法
动机
虽然大部分Kaggle竞赛获胜者使用各种模型的堆叠/集成,但是作为大部分集成的一部分的一个特定模型是梯度提升(GBM)算法的一些变体。以最新的Kaggle比赛获胜者为例:迈克尔Jahrer安全司机预测。他的解决方案是6个模型的混合。 1个LightGBM(GBM的变体)和5个神经网络。虽然他的成功归因于他将半监督学习用于结构化数据,但梯度提升模型也起到了重要作用。
尽管GBM被广泛使用,但许多从业人员仍将其视为复杂的黑盒(black-box)算法,只需使用预编译的(pre-built)库运行模型即可。这篇文章的目的是为了简化所谓的复杂算法,并帮助读者直观地理解算法。解释梯度提升算法的简介版本,并将在最后共享其不同的变体链接。我已经采用了基本的DecisionTree代码 Library (fastai /courses /ml1 /lesson3-rf_foundations.ipynb),最重要的是,我已经构建了自己的简单版本的基本梯度提升模型。
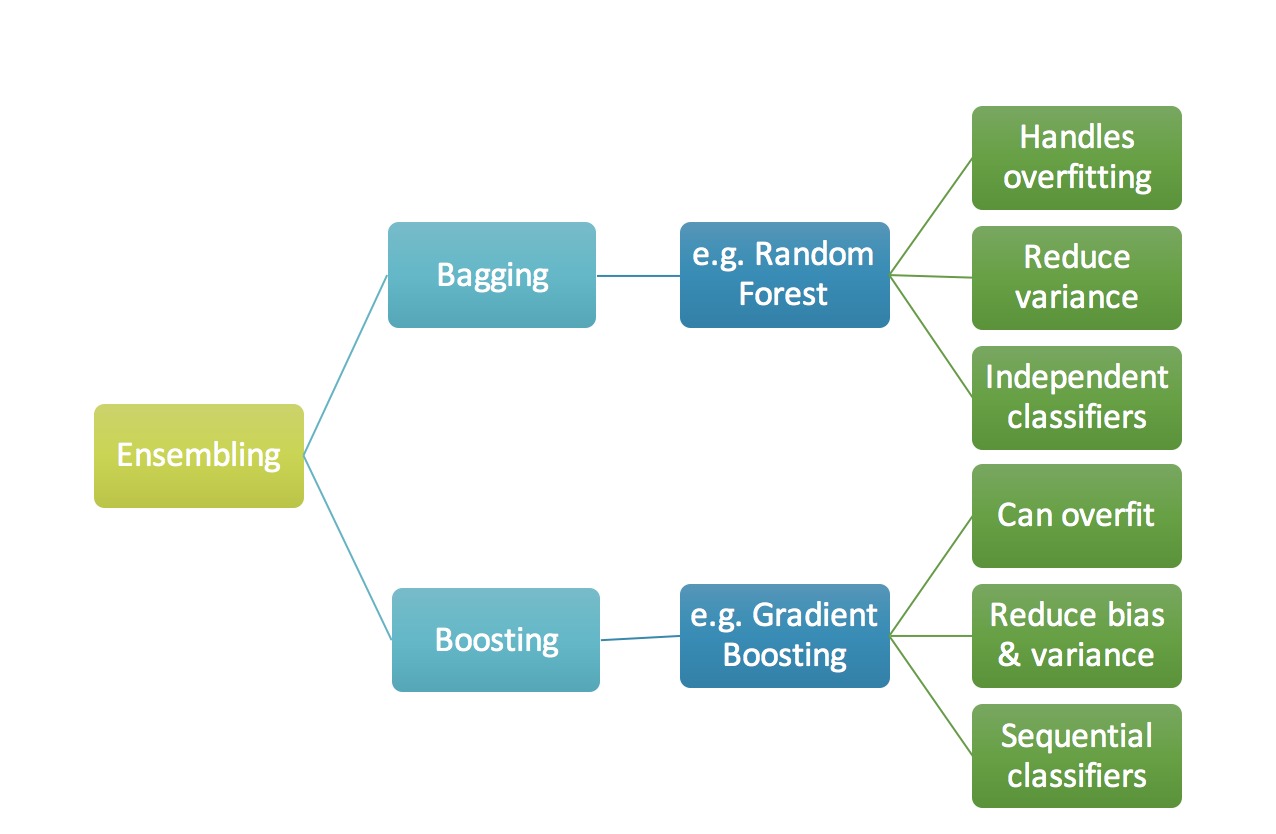
关于Ensemble,Bagging和Boosting的简要描述
当我们试图用任何机器学习技术来预测目标变量时,造成实际值和预测值之间差异的主要原因是噪音(noise),方差(variance)和偏差(bias)。集成(Ensemble)有助于减少这些因素(除了噪音,这是不可避免的错误)
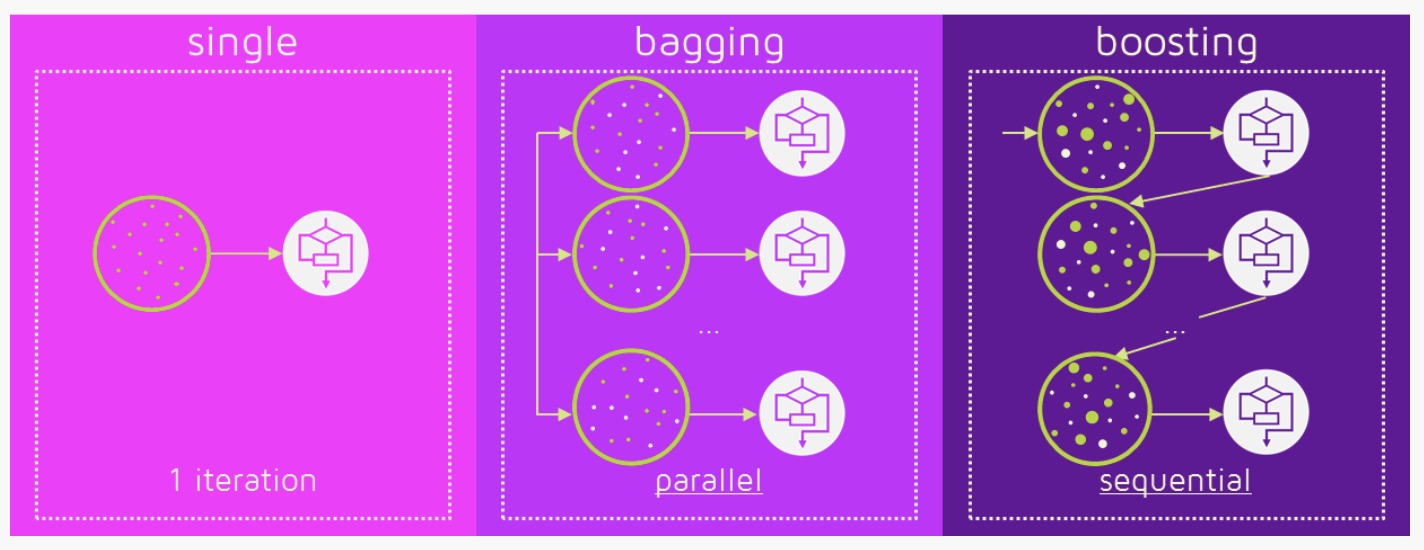
Ensemble(集成)只是汇集了一些预测变量(例如所有预测的均值)以给出最终预测。我们使用集成的原因是,许多不同的预测因素试图预测相同的目标变量,这将比任何单独的预测变量表现更好。集成技术进一步分为Bagging和Boosting。
- Bagging是一个简单的集成技术,我们在其中建立了许多独立预测因子/模型/学习器,并使用一些模型平均技术将它们结合起来。 (例如加权平均数,多数票或正常平均数)
我们通常为每个模型采用随机下采样/bootstrap数据,以便所有模型都彼此略有不同。每个观察结果出现在所有模型中的概率相同。因为这种技术需要很多不相关的学习器来制作最终模型,所以它通过减少方差(variance)来减少偏差(bias)。Bagging集成的例子是随机森林模型。
- Boosting是一种集成技术,其中预测指标不是独立制定的,而是依次进行的。
这种技术采用了后面的预测变量从以前的预测变量中学习的逻辑。因此,观测值在后续模型中出现的概率是不相等的,而最高误差值出现最多。预测因子可以从一系列模型中选择,如决策树,回归因子,分类器等。因为新的预测因子是从以前的预测因子所犯的错误中学习的,所以它需要更少的时间/迭代来接近实际的预测。但是,我们必须谨慎选择停止标准,否则可能导致过度训练数据。梯度提升是增强算法的一个例子。
梯度提升算法
梯度提升是一种用于回归和分类问题的机器学习技术,该技术以弱预测模型(通常为决策树)的集合的形式产生预测模型。(维基百科定义)
任何监督学习算法的目标是定义一个损失函数并将其最小化。让我们看看梯度提升算法的数学运算。假设我们将均方误差(MSE)定义为:

我们希望我们的预测,使我们的损失函数(MSE)最小。通过使用梯度下降并根据学习速率更新我们的预测,我们可以找到MSE最小的值。
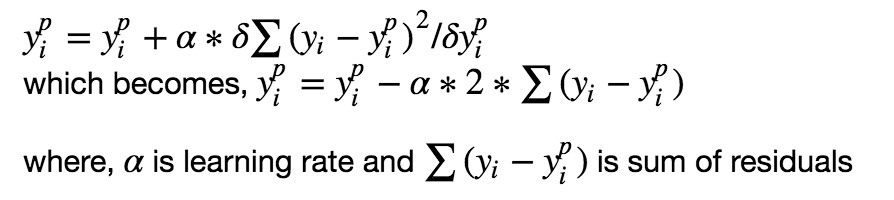
因此,我们更新预测使得我们的残差总和接近于0(或最小值),并且预测值足够接近实际值。
梯度提升的直观理解
梯度提升背后的逻辑很简单,(可以直观地理解,不使用数学符号)。我希望阅读这篇文章的人可能会很熟悉simple linear regression模型。
线性回归的一个基本假设是其残差之和为0,即残差应该在零附近随机扩散。
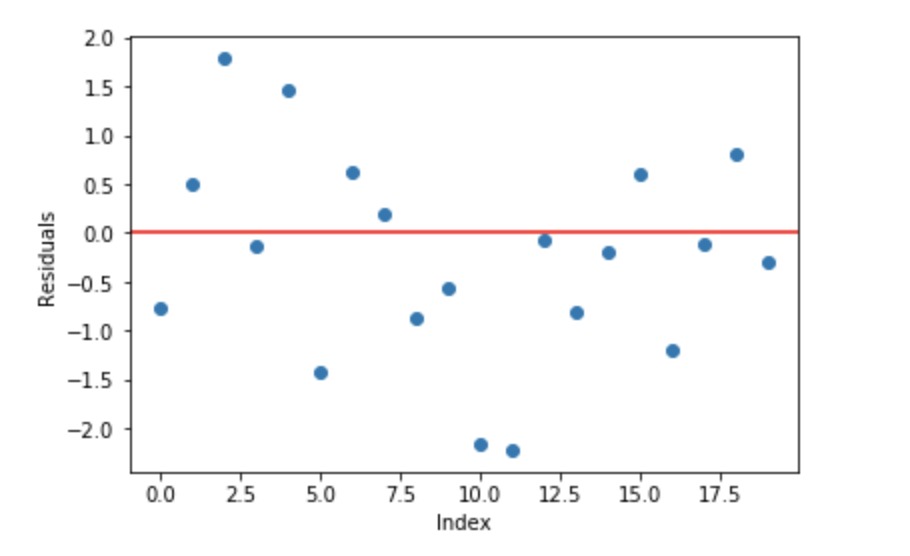
现在将这些残差视为我们的预测模型犯下的错误。虽然,树模型(考虑决策树作为我们梯度提升的基础模型)不是基于这样的假设,但如果我们从逻辑上(而不是统计上)考虑这个假设,我们可能会争辩说,如果我们能够看到0左右的残差模式,我们可以利用该模式来拟合模型。
所以,背后的直觉梯度提升(gradient boosting)算法是重复利用残差中的模式,并加强一个弱预测模型并使其更好。一旦我们达到残差没有任何可模拟模式的阶段,我们可以停止建模残差(否则可能导致过拟合)。在算法上,持续最小化损失函数,使得测试损失达到最小值。
综上所述,
•我们首先用简单的模型对数据进行建模并分析数据中的错误。
•这些错误表示难以用简单模型拟合的数据点。
•然后对于以后的模型,我们特别关注那些难以拟合的数据点,以使他们正确。
•最后,我们通过给每个预测变量赋予一些权重来组合所有预测变量。
更多背后逻辑介绍参考可能近似正确:在复杂世界中学习和繁荣的自然算法,
“这个想法是多次使用弱学习方法来获得连续的假设,每个假设重新聚焦在之前(很难并且分类错误)的例子上。
适合梯度提升模型的步骤
让我们考虑模拟数据,如下面的散点图所示,带有1个输入(x)和1个输出(y)变量。

上面显示的图的数据是使用下面的python代码生成的:
x = np.arange(0,50)
x = pd.DataFrame({'x':x})
# just random uniform distributions in differnt range
y1 = np.random.uniform(10,15,10)
y2 = np.random.uniform(20,25,10)
y3 = np.random.uniform(0,5,10)
y4 = np.random.uniform(30,32,10)
y5 = np.random.uniform(13,17,10)
y = np.concatenate((y1,y2,y3,y4,y5))
y = y[:,None]
1.在数据上拟合一个简单的线性回归器或决策树(我在我的代码中选择了决策树) [将x作为输入,将y作为输出]
xi = x # initialization of input
yi = y # initialization of target
# x,y --> use where no need to change original y
ei = 0 # initialization of error
n = len(yi) # number of rows
predf = 0 # initial prediction 0
for i in range(30): # loop will make 30 trees (n_estimators).
tree = DecisionTree(xi,yi) # DecisionTree scratch code can be found in shared github/kaggle link.
# It just create a single decision tree with provided min. sample leaf
tree.find_better_split(0) # For selected input variable, this splits (n) data so that std. deviation of
# target variable in both splits is minimum as compared to all other splits
r = np.where(xi == tree.split)[0][0] # finds index where this best split occurs
left_idx = np.where(xi <= tree.split)[0] # index lhs of split
right_idx = np.where(xi > tree.split)[0] # index rhs of split
2.计算错误残差。实际目标值,减去预测目标值[e1 = y – y_predicted1]
3.将误差残差的新模型拟合为具有相同输入变量的目标变量[称之为e1_predicted]
4.将预测残差添加到先前的预测中
[y_predicted2 = y_predicted1 + e1_predicted]
5.拟合剩余的残差模型。即[e2 = y – y_predicted2]并重复步骤2至5,直至开始过拟合或残差总和恒定。通过持续检查验证数据的准确性可以控制过度拟合。
# predictions by ith decisision tree
predi = np.zeros(n)
np.put(predi, left_idx, np.repeat(np.mean(yi[left_idx]), r)) # replace left side mean y
np.put(predi, right_idx, np.repeat(np.mean(yi[right_idx]), n-r)) # right side mean y
predi = predi[:,None] # make long vector (nx1) in compatible with y
predf = predf + predi # final prediction will be previous prediction value + new prediction of residual
ei = y - predf # needed originl y here as residual always from original y
yi = ei # update yi as residual to reloop
为了帮助理解底层概念,下面是从零开始完整实现简单梯度提升模型的链接。[链接:渐变提升]
共享代码是梯度增强的未优化基础实现。库中大多数梯度提升模型都经过了优化,并且有许多超参数。
梯度提升树的可视化
蓝点(左)图是输入(x)对输出(y)•红线(左)显示由决策树预测的值•绿点(右)显示第i次迭代的残差与输入(x)•迭代表示顺序拟合梯度提升树的顺序
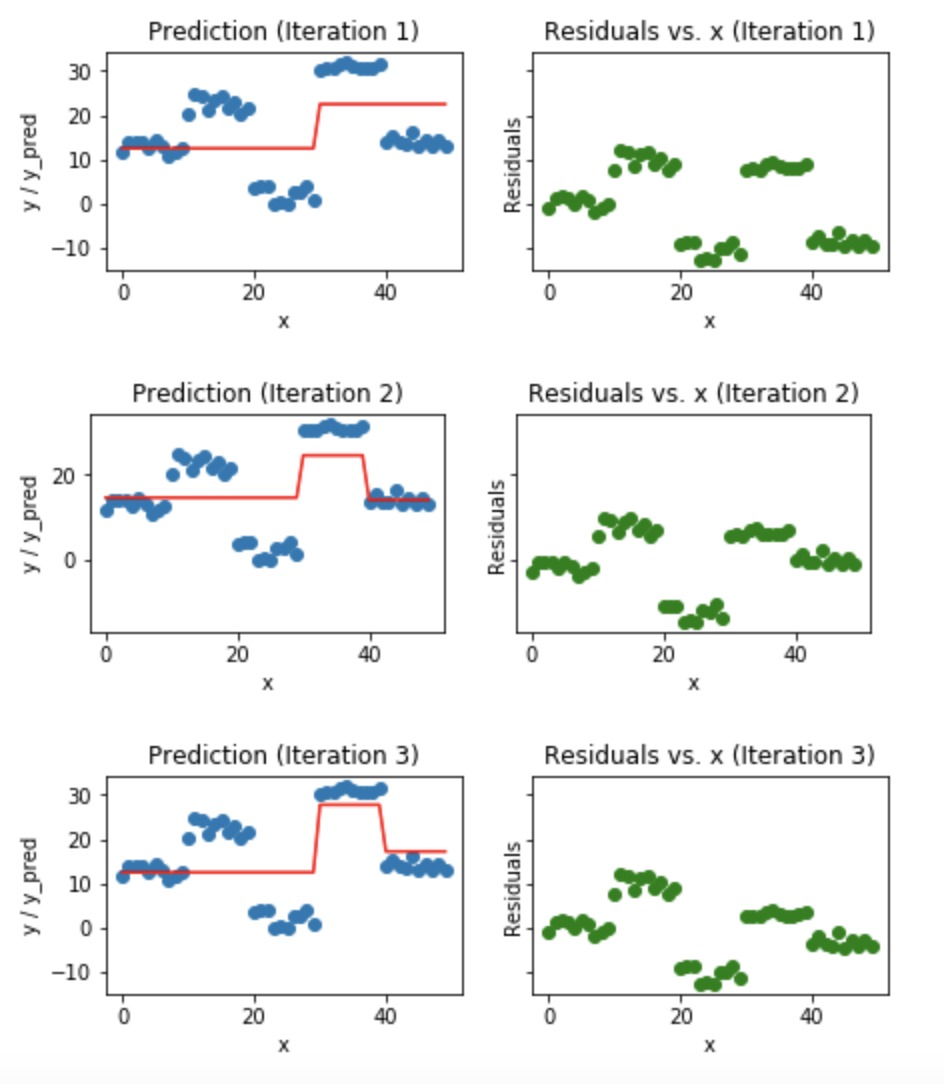
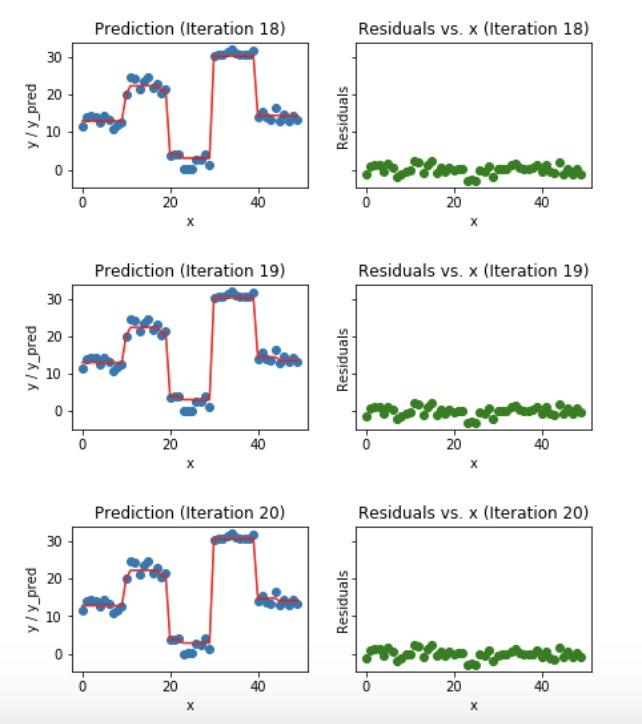
我们观察到,在第20次迭代之后,残差在0附近是随机分布的(我不是说随机正态值),我们的预测值非常接近真值。 (在sklearn实现中迭代叫做n_estimators)。这应该是一个很好的停止点或我们的模型开始过度拟合的点。
让我们看看我们的模型是如何进行第50次迭代的。
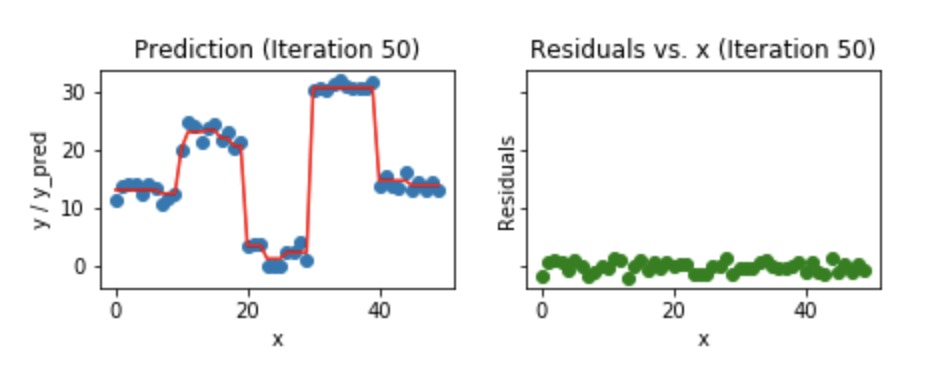
我们可以看到,即使在第50次迭代之后,残差对x的曲线看起来与我们在第20次迭代中看到的相似。但是模型变得越来越复杂,预测对训练数据过度拟合,并试图学习每个训练数据。所以,在第20次迭代停止会更好。
用于绘制所有上述数字的Python代码片段。
# plotting after prediction
xa = np.array(x.x) # column name of x is x
order = np.argsort(xa)
xs = np.array(xa)[order]
ys = np.array(predf)[order]
#epreds = np.array(epred[:,None])[order]
f, (ax1, ax2) = plt.subplots(1, 2, sharey=True, figsize = (13,2.5))
ax1.plot(x,y, 'o')
ax1.plot(xs, ys, 'r')
ax1.set_title(f'Prediction (Iteration {i+1})')
ax1.set_xlabel('x')
ax1.set_ylabel('y / y_pred')
ax2.plot(x, ei, 'go')
ax2.set_title(f'Residuals vs. x (Iteration {i+1})')
ax2.set_xlabel('x')
ax2.set_ylabel('Residuals')