pyspark中的RandomForest,也就是随机森林,既可以训练分类模型,也可以训练回归模型,下面分别介绍。
RandomForest分类
使用RondomForest建立分类模型,需要使用下面的方法:
trainClassifier(data, numClasses, categoricalFeaturesInfo, numTrees, featureSubsetStrategy='auto', impurity='gini', maxDepth=4, maxBins=32, seed=None)
trainClassifier参数说明
- data – 训练数据集:LabeledPoint的RDD。标签取值范围{0, 1, …, numClasses-1}。
- numClasses – 用于分类的类数, 可以支持二分类,也可以支持多分类。
- categoricalFeaturesInfo – 存储类别特征的Map。条目(n -> k )表示特征n被k个类别分类,索引编号 {0, 1, …, k-1}。
- numTrees – 随机森林中的树数目。
- featureSubsetStrategy – 分裂每个节点需要考虑的特征数。支持的值:“auto”, “all”, “sqrt”, “log2”, “onethird”。如果设置为“auto”,则该参数根据numTrees设置:如果numTrees == 1,设置为“all”;如果numTrees> 1(forest)设置为“sqrt”。 (默认值:“auto”)
- impurity – 用于信息增益计算的标准。支持的值:“gini”或“ entropy”。 (默认:“gini”)
- maxDepth – 树的最大深度(例如深度0表示1个叶节点,深度1表示1个内部节点+ 2个叶节点)。 (默认值:4)
- maxBins – 用于分割特征的最大bin数量。 (默认值:32)
- seed – 用于自举和选择特征子集的随机种子。设置为None则根据系统时间设置种子。 (默认值:None)
- 返回值:可用于预测的RandomForestModel。
分类的示例
>>> from pyspark.mllib.regression import LabeledPoint
>>> from pyspark.mllib.tree import RandomForest
>>>
>>> data = [
... LabeledPoint(0.0, [0.0]),
... LabeledPoint(0.0, [1.0]),
... LabeledPoint(1.0, [2.0]),
... LabeledPoint(1.0, [3.0])
... ]
### 分类模型训练
>>> model = RandomForest.trainClassifier(sc.parallelize(data), 2, {}, 3, seed=42)
>>> model.numTrees()
3
>>> model.totalNumNodes()
7
>>> print(model)
TreeEnsembleModel classifier with 3 trees
### 输出模型内容(树状结构)
>>> print(model.toDebugString())
TreeEnsembleModel classifier with 3 trees
Tree 0:
Predict: 1.0
Tree 1:
If (feature 0 <= 1.0)
Predict: 0.0
Else (feature 0 > 1.0)
Predict: 1.0
Tree 2:
If (feature 0 <= 1.0)
Predict: 0.0
Else (feature 0 > 1.0)
Predict: 1.0
### 分类预测
>>> model.predict([2.0])
1.0
>>> model.predict([0.0])
0.0
>>> rdd = sc.parallelize([[3.0], [1.0]])
>>> model.predict(rdd).collect()
[1.0, 0.0]
RomdomForest回归
使用RondomForest建立回归模型,需要使用下面的方法:
trainRegressor(data, categoricalFeaturesInfo, numTrees, featureSubsetStrategy='auto', impurity='variance', maxDepth=4, maxBins=32, seed=None)
trainRegressor参数说明
- data – 训练数据集:LabeledPoint的RDD。标签是实数。
分类categoricalFeaturesInfo信息 – 存储类别特征的Map。条目(n -> k )表示特征n被k个类别分类,索引编号 {0, 1, …, k-1}。 - numTrees – 随机森林中的树数目。
- featureSubsetStrategy – 分裂每个节点需要考虑的特征数。支持的值:“auto”, “all”, “sqrt”, “log2”, “onethird”。如果设置为“auto”,则该参数根据numTrees设置:如果numTrees == 1,设置为“all”;如果numTrees> 1(forest)设置为“onethird”进行回归。 (默认值:“auto”)
- impurity – 用于信息增益计算的标准。唯一支持的回归值是“variance”。 (默认值:“ variance”)
- maxDepth – 树的最大深度(例如深度0表示1个叶节点,深度1表示1个内部节点+ 2个叶节点)。 (默认值:4)
- maxBins – 用于分割特征的最大bin数量。 (默认值:32)
- seed – 用于自举和选择特征子集的随机种子。设置为None则根据系统时间设置种子。 (默认值:None)
- 返回值:可用于预测的RandomForestModel。
回归的示例
>>> from pyspark.mllib.regression import LabeledPoint
>>> from pyspark.mllib.tree import RandomForest
>>> from pyspark.mllib.linalg import SparseVector
>>>
>>> sparse_data = [
... LabeledPoint(0.0, SparseVector(2, {0: 1.0})),
... LabeledPoint(1.0, SparseVector(2, {1: 1.0})),
... LabeledPoint(0.0, SparseVector(2, {0: 1.0})),
... LabeledPoint(1.0, SparseVector(2, {1: 2.0}))
... ]
>>>
### 回归模型训练
>>> model = RandomForest.trainRegressor(sc.parallelize(sparse_data), {}, 2, seed=42)
>>> model.numTrees()
2
>>> model.totalNumNodes()
4
### 回归预测
>>> model.predict(SparseVector(2, {1: 1.0}))
1.0
>>> model.predict(SparseVector(2, {0: 1.0}))
0.5
>>> rdd = sc.parallelize([[0.0, 1.0], [1.0, 0.0]])
>>> model.predict(rdd).collect()
[1.0, 0.5]
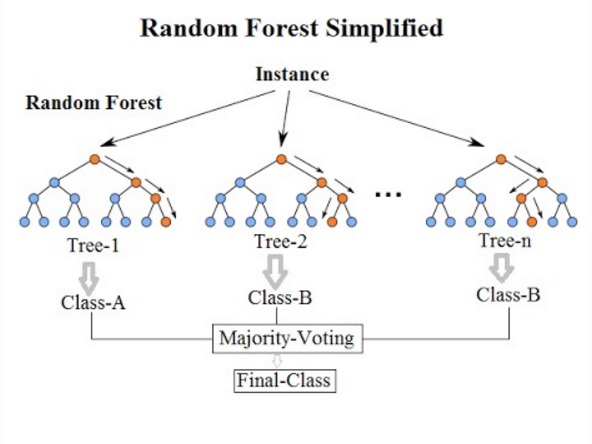
pyspark RandomForest的最新介绍参见:RandomForest