布隆過濾器用於確定元素是否存在於集合中的集合成員資格set或不。布隆過濾器的發明者伯頓·H·布魯姆1970 年,在一篇名為允許錯誤的哈希編碼中的空間/時間Trade-offs (1970)。布隆過濾器是一種概率數據結構,適用於hash-coding方法(如同HashTable)。
我們什麽時候需要布隆過濾器?
考慮以下任一情況:
- 假設我們有一個包含一些元素的列表,並且我們想檢查給定元素是否存在?
- 考慮您正在開發電子郵件服務,並且您正在嘗試使用給定用戶名已經存在或不存在的函數來實現注冊端點?
- 假設您給出了一組列入黑名單的 IP,並且您想過濾掉給定的 IP 是否屬於黑名單?
如果沒有布隆過濾器的幫助,這些問題可以解決嗎?
讓我們嘗試使用HashSet來解決這些問題
import java.util.HashSet;
import java.util.Set;
public class SetDemo {
public static void main(String[] args)
{
Set<String> blackListedIPs
= new HashSet<>();
blackListedIPs.add("192.170.0.1");
blackListedIPs.add("75.245.10.1");
blackListedIPs.add("10.125.22.20");
// true
System.out.println(
blackListedIPs
.contains(
"75.245.10.1"));
// false
System.out.println(
blackListedIPs
.contains(
"101.125.20.22"));
}
} true false
為什麽像HashSet或HashTable這樣的數據結構會失敗?
當我們的數據集有限時,HashSet 或 HashTable 效果很好,但當我們處理大量數據集時,可能不適合。對於大數據集,需要大量時間和大量內存。
數據集大小與 HashSet 等數據結構的插入時間
---------------------------------------------- |Number of UUIDs Insertion Time(ms) | ---------------------------------------------- |10 <1 | |100 3 | |1, 000 58 | |10, 000 122 | |100, 000 836 | |1, 000, 000 7395 | ----------------------------------------------
數據集大小與 HashSet 等數據結構的 memory (JVM Heap)
---------------------------------------------- |Number of UUIDs JVM heap used(MB) | ---------------------------------------------- |10 <2 | |100 <2 | |1, 000 3 | |10, 000 9 | |100, 000 37 | |1, 000, 000 264 | -----------------------------------------------
所以很明顯,如果我們有一個大的數據集,那麽像 Set 或 HashTable 這樣的普通數據結構是不可行的,這裏布隆過濾器就派上用場了。有關兩者比較的更多詳細信息,請參閱本文:Difference between Bloom filters and Hashtable
如何借助Bloom Filter來解決這些問題呢?
讓我們來看一個位數組大小的N(這裏是 24)並用二進製零初始化每個位,現在取一些散列函數(你可以取任意多個,我們在這裏取兩個哈希函數來進行說明)。
![]()
- 現在將您擁有的第一個 IP 傳遞給兩個哈希函數,該函數會生成一些隨機數,如下所示
hashFunction_1(192.170.0.1) : 2 hashFunction_2(192.170.0.1) : 6
現在,轉到索引 2 和 6 並將該位標記為二進製 1。

- 現在傳遞您擁有的第二個IP,並按照相同的步驟操作。
hashFunction_1(75.245.10.1) : 4 hashFunction_2(75.245.10.1) : 10
現在,轉到索引 4 和 10 並將該位標記為二進製 1。

- 同樣將第三個 IP 傳遞給兩個哈希函數,並假設您得到了哈希函數的以下輸出
hashFunction_1(10.125.22.20) : 10 hashFunction_2(10.125.22.20) : 19
'
現在,轉到索引 10 和 19 並將其標記為二進製 1,這裏索引 10 已被前一個條目標記,因此隻需將索引 19 標記為二進製 1。
- 測試輸入#1
假設我們要檢查 IP75.245.10.1。使用我們用於添加上述輸入的相同的兩個哈希函數傳遞此 IP。hashFunction_1(75.245.10.1) : 4 hashFunction_2(75.245.10.1) : 10
現在,轉到索引並檢查該位,如果索引 4 和 10 都標記為二進製 1,則 IP 75.245.10.1 存在於集合中,否則它不存在於數據集中。
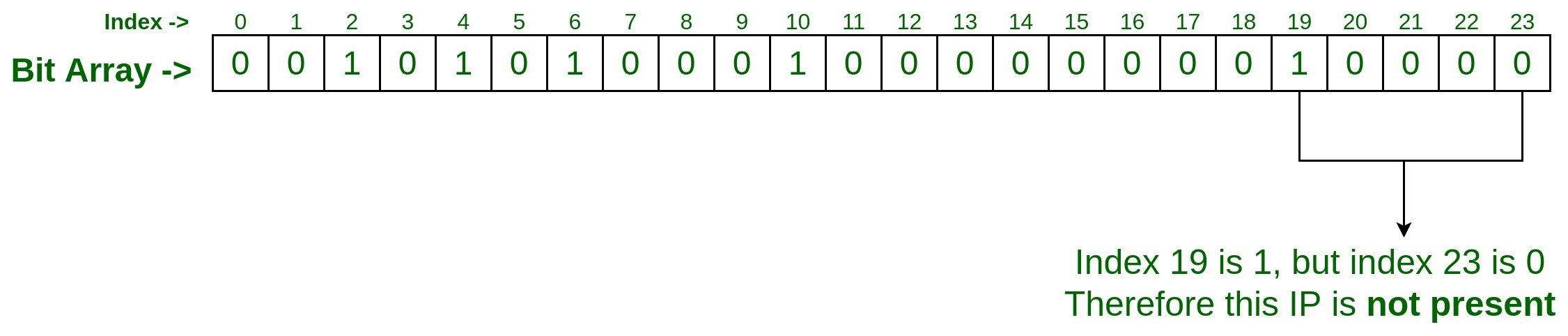
- 測試輸入#2
假設我們要檢查 IP75.245.20.30是否存在於集合中?因此,過程將是相同的,使用我們用於添加上述輸入的相同的兩個哈希函數傳遞此 IP。hashFunction_1(75.245.20.30) : 19 hashFunction_2(75.245.20.30) : 23
由於在索引 19 處它被設置為 1,但在索引 23 處它被設置為 0,所以我們可以說給定的 IP 75.245.20.30 不存在於集合中。




現在,是時候檢查數據集中是否存在 IP 了,


為什麽布隆過濾器是概率數據結構?
讓我們通過另一個測試來理解這一點,這次考慮一個 IP101.125.20.22並檢查它是否存在於集合中。將其傳遞給兩個哈希函數。考慮我們的哈希函數結果如下。
hashFunction_1(101.125.20.22) : 19 hashFunction_2(101.125.20.22) : 2
現在,訪問索引 19 和 2(設置為 1),它表示給定的 IP101.125.20.22 存在於集合中。

但是,這個 IP 101.125.20.22 已在上麵的數據集中進行了處理,同時將 IP 添加到位數組中。這稱為誤報:
Expected Output: No Actual Output: Yes (False Positive)
在本例中,索引 2 和 19 被其他輸入設置為 1,而不是被該 IP 101.125.20.22 設置為 1。這就是所謂的碰撞,這就是為什麽它是概率性的,發生的可能性不是 100%。
對布隆過濾器有何期望?
- 當布隆過濾器表示某個元素是不存在這是肯定不存在。它保證 100% 給定的元素在集合中不可用,因為哈希函數給出的索引的任何一位都將被設置為 0。
- 但是當布隆過濾器說給定元素是展示這是不是100%確定,因為可能由於衝突,哈希函數給出的索引的所有位都被其他輸入設置為 1。
如何從布隆過濾器獲得 100% 準確的結果?
那麽,這隻能通過采用更多數量的哈希函數來實現。我們采用的哈希函數數量越多,得到的結果就越準確,因為發生衝突的機會就越小。
布隆過濾器的時間和空間複雜度
假設我們周圍有4000萬個數據集我們正在使用周圍H 哈希函數, 然後:
Time complexity: O(H), where H is the number of hash functions used
Space complexity: 159 Mb (For 40 million data sets)
Case of False positive: 1 mistake per 10 million (for H = 23)
使用 Guava 庫在 Java 中實現布隆過濾器:
我們可以使用以下方法來實現布隆過濾器Guava 提供的 Java 庫.
- 包括以下 Maven 依賴項:
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>19.0</version> </dependency> - 編寫以下代碼來實現布隆過濾器:
// Java program to implement // Bloom Filter using Guava Library import java.nio.charset.Charset; import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; public class BloomFilterDemo { public static void main(String[] args) { // Create a Bloom Filter instance BloomFilter<String> blackListedIps = BloomFilter.create( Funnels.stringFunnel( Charset.forName("UTF-8")), 10000); // Add the data sets blackListedIps.put("192.170.0.1"); blackListedIps.put("75.245.10.1"); blackListedIps.put("10.125.22.20"); // Test the bloom filter System.out.println( blackListedIps .mightContain( "75.245.10.1")); System.out.println( blackListedIps .mightContain( "101.125.20.22")); } }輸出:
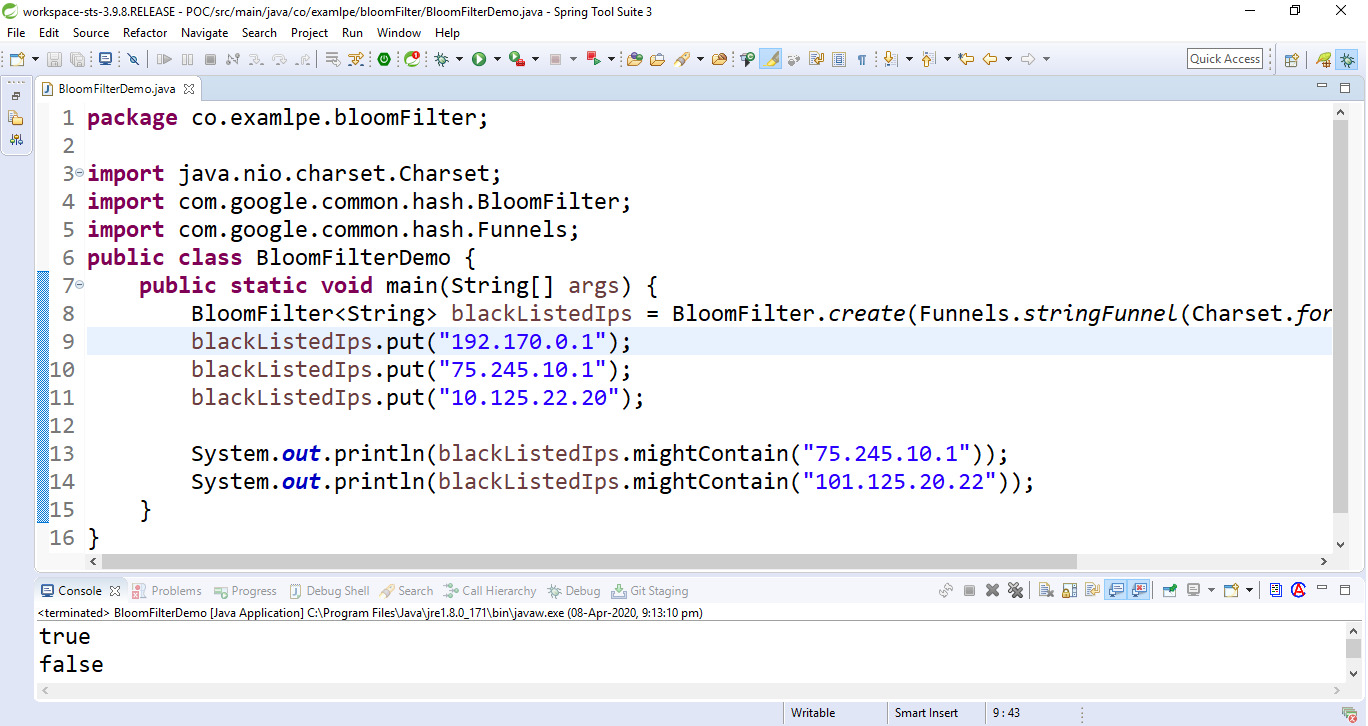
布隆過濾器輸出
Note: The above Java code may return a 3% false-positive probability by default.
- 降低false-positive概率
在Bloom Filter對象創建中引入另一個參數,如下:
BloomFilterblackListedIps = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), 10000, 0.005);
現在false-positive概率已從0.03減少到0.005。但調整此參數會對布隆過濾器產生影響。

降低誤報概率的效果:
我們從哈希函數、數組位、時間複雜度和空間複雜度來分析這種影響。
- 讓我們看看不同數據集的插入時間。
----------------------------------------------------------------------------- |Number of UUIDs | Set Insertion Time(ms) | Bloom Filter Insertion Time(ms) | ----------------------------------------------------------------------------- |10 <1 71 | |100 3 17 | |1, 000 58 84 | |10, 000 122 272 | |100, 000 836 556 | |1, 000, 000 7395 5173 | ------------------------------------------------------------------------------
- 現在,讓我們看一下內存(JVM 堆)
-------------------------------------------------------------------------- |Number of UUIDs | Set JVM heap used(MB) | Bloom filter JVM heap used(MB) | -------------------------------------------------------------------------- |10 <2 0.01 | |100 <2 0.01 | |1, 000 3 0.01 | |10, 000 9 0.02 | |100, 000 37 0.1 | |1, 000, 000 264 0.9 | ---------------------------------------------------------------------------
- 位計數
---------------------------------------------- |Suggested size of Bloom Filter | Bit count | ---------------------------------------------- |10 40 | |100 378 | |1, 000 3654 | |10, 000 36231 | |100, 000 361992 | |1, 000, 000 3619846 | -----------------------------------------------
- 用於各種誤報概率的哈希函數數量:
----------------------------------------------- |Suggested FPP of Bloom Filter | Hash Functions| ----------------------------------------------- |3% 5 | |1% 7 | |0.1% 10 | |0.01% 13 | |0.001% 17 | |0.0001% 20 | ------------------------------------------------
結論:
因此可以說,當我們必須以低內存消耗處理大數據集的情況下,布隆過濾器是一個不錯的選擇。此外,我們想要更準確的結果,必須增加哈希函數的數量。
相關用法
- Java BlockingDeque add()用法及代碼示例
- Java BlockingDeque addFirst()用法及代碼示例
- Java BlockingDeque addLast()用法及代碼示例
- Java BlockingDeque contains()用法及代碼示例
- Java BlockingDeque element()用法及代碼示例
- Java BlockingDeque iterator()用法及代碼示例
- Java BlockingDeque offerFirst()用法及代碼示例
- Java BlockingDeque offerLast()用法及代碼示例
- Java BlockingDeque peek()用法及代碼示例
- Java BlockingDeque poll()用法及代碼示例
- Java BlockingDeque pollFirst()用法及代碼示例
- Java BlockingDeque pollLast()用法及代碼示例
- Java BlockingDeque push()用法及代碼示例
- Java BlockingDeque put()用法及代碼示例
- Java BlockingDeque putFirst()用法及代碼示例
- Java BlockingDeque remove()用法及代碼示例
- Java BlockingDeque removeFirstOccurrence()用法及代碼示例
- Java BlockingDeque removeLastOccurrence()用法及代碼示例
- Java BlockingDeque size()用法及代碼示例
- Java BlockingDeque take()用法及代碼示例
- Java BlockingDeque takeFirst()用法及代碼示例
- Java BlockingDeque takeLast()用法及代碼示例
- Java BlockingQueue add()用法及代碼示例
- Java BlockingQueue contains()用法及代碼示例
- Java BlockingQueue drainTo()用法及代碼示例
注:本文由純淨天空篩選整理自asadaliasad大神的英文原創作品 Bloom Filter in Java with Examples。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。