在本文中,我们将从sklearn库中了解StratifiedShuffleSplit交叉验证器,该验证器提供train-test索引以将数据分为train-test集。
什么是StratifiedShuffleSplit?
分层洗牌拆分是ShuffleSplit和StratifiedKFold的组合。使用StratifiedShuffleSplit,训练和测试数据集之间的类标签分布比例几乎相等。 StratifiedShuffleSplit和StratifiedKFold(shuffle = True)之间的主要区别在于,在StratifiedKFold中,数据集仅在开始时被随机洗一次,然后分成指定的折叠数。这将丢弃train-test集重叠的任何机会。但是,在StratifiedShuffleSplit中,每次在拆分完成之前都会对数据进行混洗,这就是为什么在train-test集之间有更大可能重叠的原因。
用法:sklearn.model_selection.StratifiedShuffleSplit(n_splits=10, *, test_size=None, train_size=None, random_state=None)
参数:
n_splits:int,默认= 10
re-shuffling和拆分迭代的次数。
test_size:float或int,默认为None
如果为float,则应在0.0到1.0之间,并且代表要包含在测试拆分中的数据集的比例。
train_size:float或int,默认为None
如果为float,则应在0.0到1.0之间,并且代表要包含在火车分割中的数据集的比例。
random_state:整型
控制所产生的训练和测试指标的随机性。
下面是实现。
步骤1)导入所需的模块。
Python3
# import the libraries
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedShuffleSplit步骤2)加载数据集并标识因变量和自变量。
数据集可从此处下载。
Python3
# convert data set into dataframe
churn_df = pd.read_csv(r"ChurnData.csv")
# assign dependent and indepenedent variables
X = churn_df[['tenure', 'age', 'address', 'income',
'ed', 'employ', 'equip', 'callcard', 'wireless']]
y = churn_df['churn'].astype('int')步骤3)预处理数据。
Python3
# data pre-processing
X = preprocessing.StandardScaler().fit(X).transform(X)步骤4)创建StratifiedShuffleSplit类的对象。
Python3
# use StratifiedShuffleSplit()
sss = StratifiedShuffleSplit(n_splits=4, test_size=0.5,
random_state=0)
sss.get_n_splits(X, y)输出:

步骤5)调用实例并将数据帧分为训练样本和测试样本。 split()函数返回train-test个样本的索引。使用回归算法并比较每个预测值的准确性。
Python3
scores = []
# using regression to get predicted data
rf = RandomForestClassifier(n_estimators=40, max_depth=7)
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
rf.fit(X_train, y_train)
pred = rf.predict(X_test)
scores.append(accuracy_score(y_test, pred))
# get accurracy of each prediction
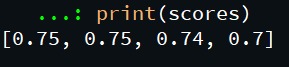
print(scores)输出:
注:本文由纯净天空筛选整理自 Sklearn.StratifiedShuffleSplit() function in Python。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。