Seaborn是一个了不起的可视化库,用于在Python中进行统计图形绘制。它提供了漂亮的默认样式和调色板,以使统计图更具吸引力。它建立在matplotlib库的顶部,并与 Pandas 的数据结构紧密集成。
seaborn.lmplot()方法
seaborn.lmplot()方法用于将散点图绘制到FacetGrid上。
用法: seaborn.lmplot(x, y, data, hue=None, col=None, row=None, palette=None, col_wrap=None, height=5, aspect=1, markers=’o’, sharex=True, sharey=True, hue_order=None, col_order=None, row_order=None, legend=True, legend_out=True, x_estimator=None, x_bins=None, x_ci=’ci’, scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None, size=None)
参数:此方法接受下面描述的以下参数:
- x, y:(可选)此参数是数据中的列名。
- data:此参数是DataFrame。
- hue, col, row:此参数是数据的定义子集,这些子集将绘制在网格的不同面上。请参阅* _order参数以控制此变量的级别顺序。
- palette:(可选)此参数是调色板名称,列表或字典,用于不同级别的hue变量的颜色。应该是可以由color_palette()解释的内容,或者是将色相级别映射到matplotlib颜色的字典。
- col_wrap:(可选)此参数为int类型,“Wrap”具有此宽度的列变量,以便列构面跨越多行。与行构面不兼容。
- height:(可选)此参数是每个构面的高度(以英寸为单位)。
- aspect:(可选)此参数是每个构面的纵横比,因此,aspect * height给出每个构面的宽度(以英寸为单位)。
- markers:(可选)此参数是matplotlib标记代码或标记代码列表,散点图的标记。如果是列表,列表中的每个标记将用于每个级别的色相变量。
- share{x, y}:(可选)此参数为布尔型‘col’或‘row’。如果为true,则构面将共享列的y轴和/或行的x轴。
- {hue,col,row} _order:(可选)此参数是列表,是构面变量级别的顺序。默认情况下,这将是级别在数据中出现的顺序;如果变量是pandas类别,则将是类别顺序。
- legend:(可选)此参数接受bool值,如果为True且有色相变量,请添加图例。
- legend_out:(可选)此参数接受bool值,如果为True,则图形尺寸将被扩展,并且图例将绘制在右中图的外部。
- x_estimator:(可选)可调用此参数以映射向量->标量,将此函数应用于x的每个唯一值并绘制结果估计。当x是离散变量时,这很有用。如果给出x_ci,则该估计将被引导并绘制置信区间。
- x_bins:(可选)此参数为int或vector,将x变量绑定到离散的bin中,然后估计中心趋势和置信区间。这种装箱仅影响散点图的绘制方式;回归仍然适合原始数据。此参数被解释为evenly-sized(不需要间隔)的存储箱数或存储箱中心的位置。使用此参数时,表示x_estimator的默认值为numpy.mean。
- x_ci:(可选)此参数为“ci”,“sd”,[0,100]中的int或“无”,为x的离散值绘制中心趋势时使用的置信区间的大小。如果为“ci”,则遵循ci参数的值。如果为“sd”,请跳过引导程序,并显示每个仓中观测值的标准偏差。
- scatter:(可选)此参数接受bool值。如果为True,则使用基础观测值(或x_estimator值)绘制散点图。
- fit_reg:(可选)此参数接受bool值。如果为True,则估计并绘制与x和y变量相关的回归模型。
- ci:(可选)此参数为int,为[0,100]或无,回归估计的置信区间的大小。这将使用回归线周围的半透明带绘制。置信区间是使用自举估算的;对于大型数据集,建议将此参数设置为“无”以避免计算。
- n_boot:(可选)此参数是用于估计ci的引导程序重采样数。缺省值试图平衡时间和稳定性。您可能想增加“final”版图的此值。
- units:(可选)此参数是数据中的变量名称。如果x和y观测值嵌套在采样单位内,则可以在此处指定这些观测值。在通过执行对单元和观测值(单元内)都重新采样的多级引导程序来计算置信区间时,将考虑到这一点。否则,这不会影响回归的估计或绘制方式。
- seed:(可选)此参数是int,numpy.random.Generator或numpy.random.RandomState,Seed或用于可重引导的随机数生成器。
- order:(可选)此参数的阶数大于1,使用numpy.polyfit估计多项式回归。
- logistic:(可选)此参数接受布尔值,如果为True,则假定y是二进制变量,并使用statsmodels估计逻辑回归模型。请注意,这比线性回归的计算量大得多,因此您可能希望减少引导程序重采样(n_boot)的次数或将ci设置为None。
- lowess:(可选)此参数接受bool值,如果为True,则使用statsmodels估计非参数的lowess模型(局部加权线性回归)。请注意,目前无法为这种模型绘制置信区间。
- robust:(可选)此参数接受布尔值,如果为True,则使用statsmodels估计稳健的回归。这将是de-weight个异常值。请注意,这比标准线性回归的计算量大得多,因此您可能希望减少引导程序重采样的次数(n_boot)或将ci设置为None。
- logx:(可选)此参数接受布尔值。如果为True,则估计形式为y〜log(x)的线性回归,但在输入空间中绘制散点图和回归模型。请注意,x必须为正数才能起作用。
- {x,y} _partial:(可选)此参数是数据或矩阵中的字符串,混淆变量以在绘制之前从x或y变量中回归。
- truncate:(可选)此参数接受布尔值。如果为True,则回归线受数据限制的限制。如果为False,则延伸到x轴限制。
- {x,y} _jitter:(可选)此参数是将此大小的均匀随机噪声添加到x或y变量中。拟合回归后,噪声会添加到数据副本中,并且只会影响散点图的外观。在绘制采用离散值的变量时,这可能会有所帮助。
- {scatter,line} _kws:(可选)词典
返回值:此方法返回上面带有图的FacetGrid对象,以进行进一步调整。
注意:要下载提示数据集,请单击此处。
以下示例说明了Seaborn库的lmplot()方法。
范例1:带有回归线的散点图(默认情况下)。
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
# scatter plot with regression
# line(by default)
sns.lmplot(x ='total_bill', y ='tip', data = df)
# Show the plot
plt.show()输出:
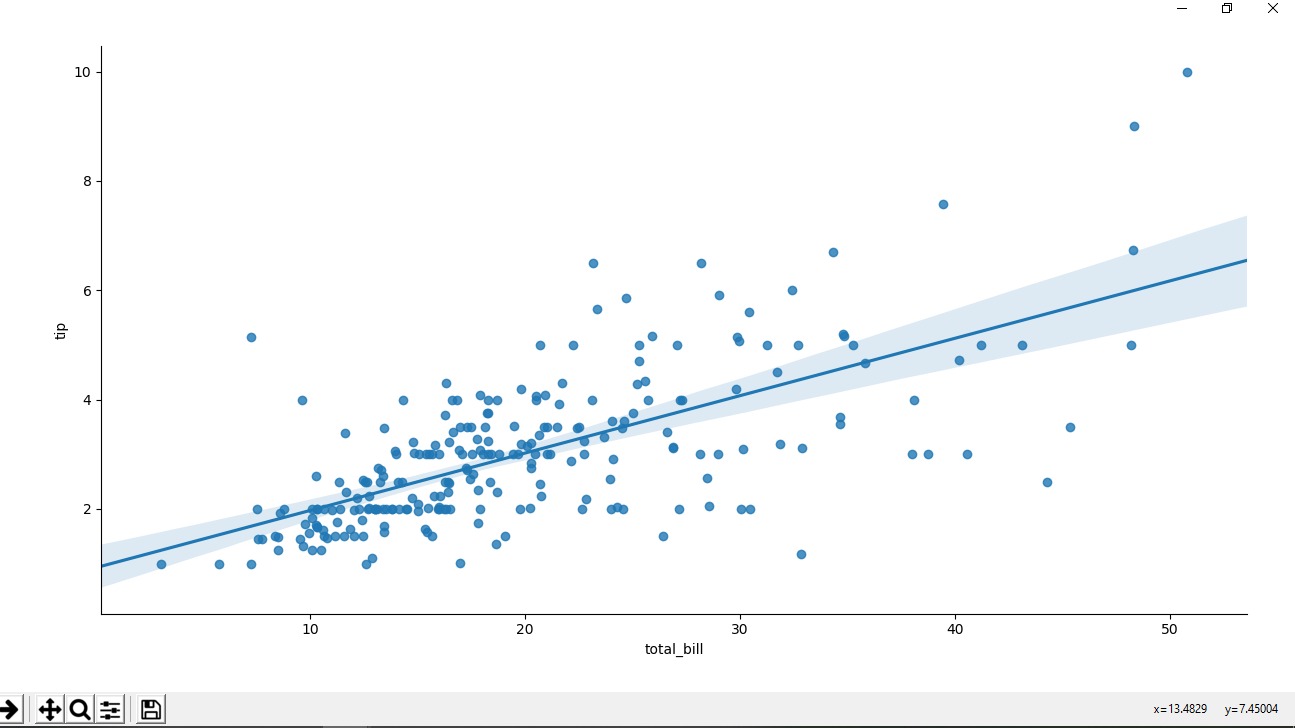
范例2:没有回归线的散点图。
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
# scatter plot without regression
# line.
sns.lmplot(x ='total_bill', y ='tip',
fit_reg = False, data = df)
# Show the plot
plt.show()输出:
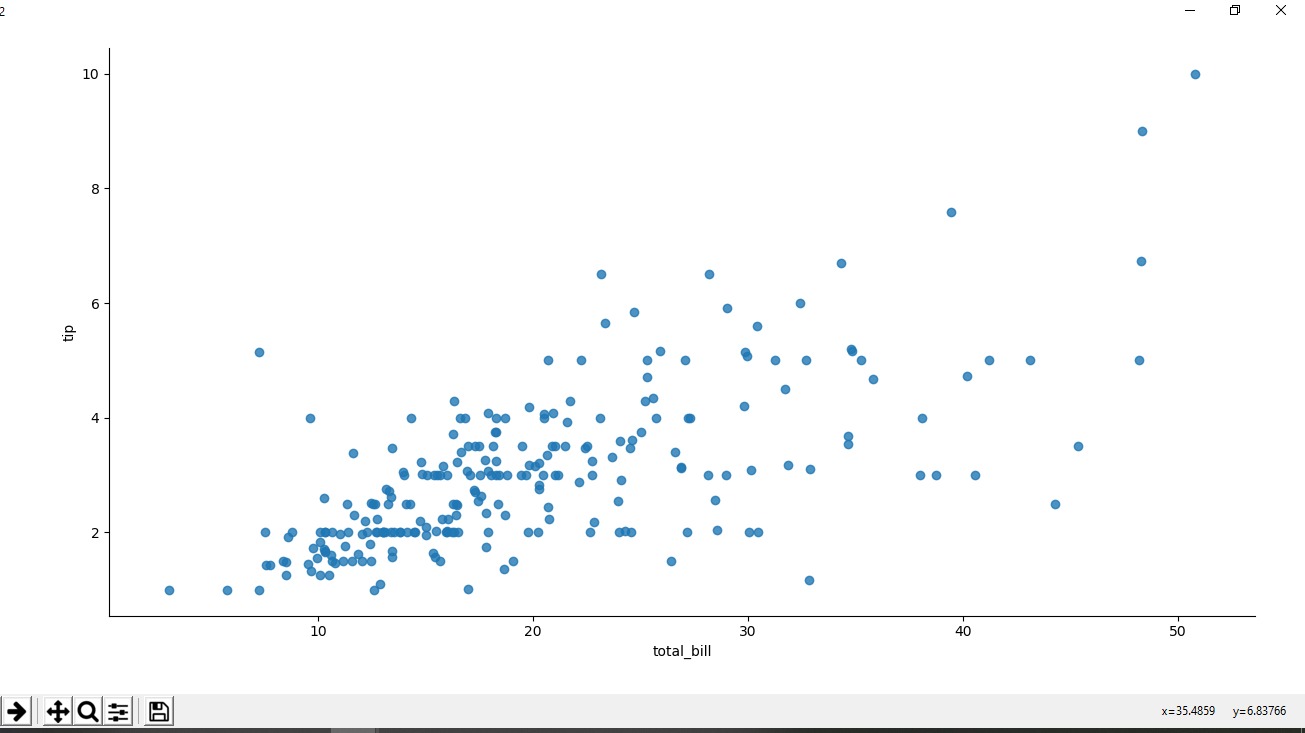
范例3:使用色相属性的散点图,用于根据性别对点进行着色。
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
# scatter plot using hue attribute
# for colouring out points
# according to the sex
sns.lmplot(x ='total_bill', y ='tip',
fit_reg = False, hue = 'sex',
data = df)
# Show the plot
plt.show()输出:
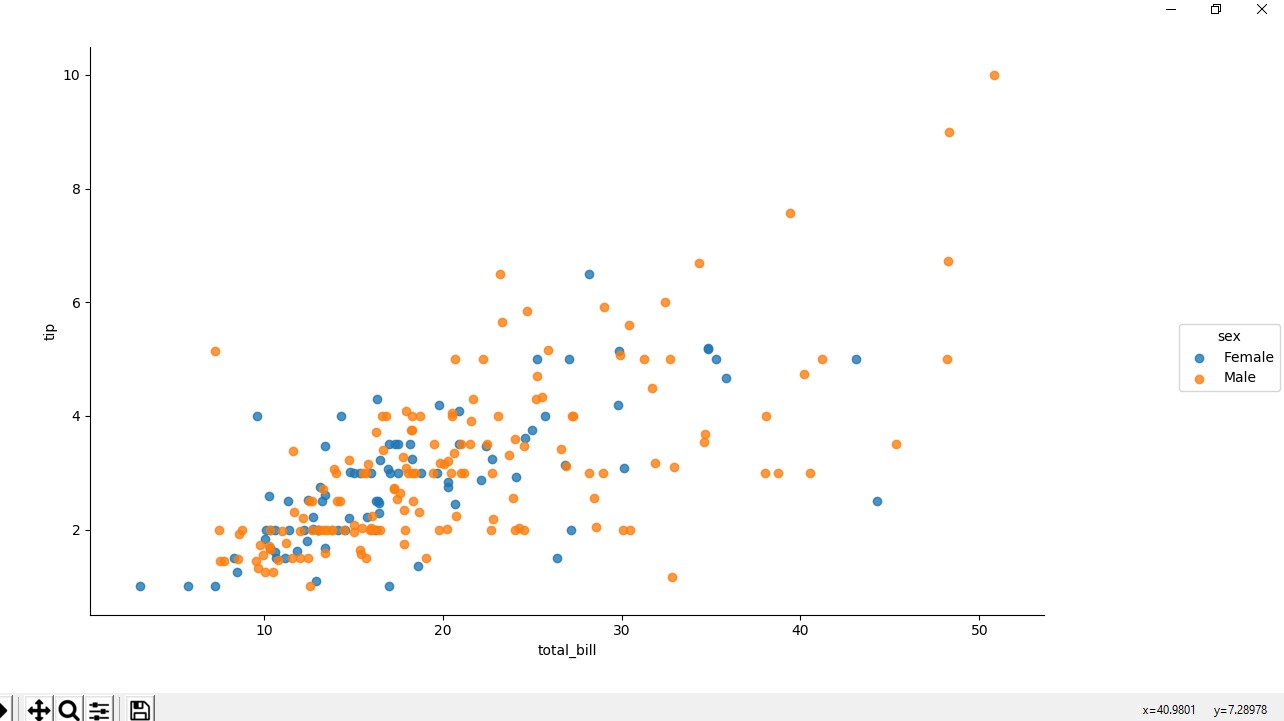
相关用法
- Python os._exit()用法及代码示例
- Python os.WEXITSTATUS()用法及代码示例
- Python os.abort()用法及代码示例
- Python os.renames()用法及代码示例
- Python os.lseek()用法及代码示例
- Python calendar formatmonth()用法及代码示例
- Python PyTorch sin()用法及代码示例
- Python Sympy Line.is_parallel()用法及代码示例
- Python PIL GaussianBlur()用法及代码示例
- Python range()用法及代码示例
- Python Numpy np.hermefit()用法及代码示例
- Python Numpy np.hermevander()用法及代码示例
注:本文由纯净天空筛选整理自AnkitRai01大神的英文原创作品 Python – seaborn.lmplot() method。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。