在PostgreSQL中,RANK()函数用于为结果集的每一行分配一个等级。RANK()函数为结果集分区中的每一行分配一个等级。对于每个分区,第一行的等级为1。RANK()函数将绑定行的数量添加到绑定等级中,以计算下一行的等级,因此这些等级可能不是顺序的。此外,具有相同值的行将获得相同的排名。
下面说明了RANK()函数的语法:
用法:
RANK() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
让我们分析以上语法:
- 首先,PARTITION BY子句将结果集的行分布到应用了RANK()函数的分区中。
- 然后,ORDER BY子句指定该函数应用到的每个分区中的行顺序。
范例1:
首先,创建一个表命名等级包含一列:
CREATE TABLE ranks (
c VARCHAR(10)
);
现在向其中添加一些数据:
INSERT INTO ranks(c)
VALUES('A'), ('A'), ('B'), ('B'), ('B'), ('C'), ('E');
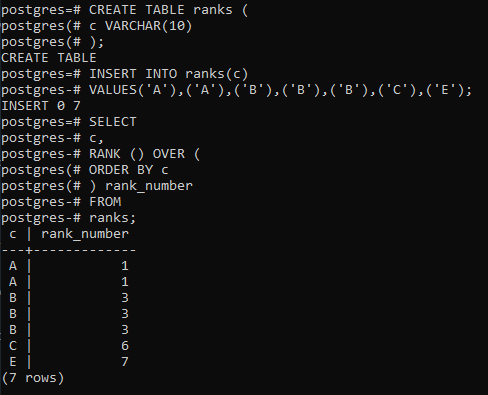
现在,使用RANK()用于将排名分配给以下结果集中的行的函数等级表:
SELECT
c,
RANK () OVER (
ORDER BY c
) rank_number
FROM
ranks;
输出:
范例2:
首先,创建两个名为product和product_groups的表:
CREATE TABLE product_groups (
group_id serial PRIMARY KEY,
group_name VARCHAR (255) NOT NULL
);
CREATE TABLE products (
product_id serial PRIMARY KEY,
product_name VARCHAR (255) NOT NULL,
price DECIMAL (11, 2),
group_id INT NOT NULL,
FOREIGN KEY (group_id) REFERENCES product_groups (group_id)
);
现在向其中添加一些数据:
INSERT INTO product_groups (group_name)
VALUES
('Smartphone'),
('Laptop'),
('Tablet');
INSERT INTO products (product_name, group_id, price)
VALUES
('Microsoft Lumia', 1, 200),
('HTC One', 1, 400),
('Nexus', 1, 500),
('iPhone', 1, 900),
('HP Elite', 2, 1200),
('Lenovo Thinkpad', 2, 700),
('Sony VAIO', 2, 700),
('Dell Vostro', 2, 800),
('iPad', 3, 700),
('Kindle Fire', 3, 150),
('Samsung Galaxy Tab', 3, 200);
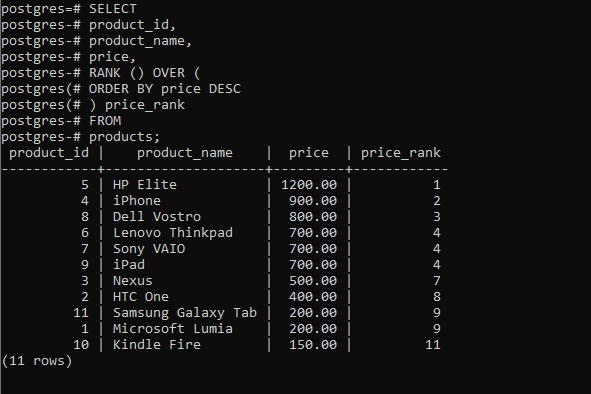
以下声明使用RANK()用于通过价格为每个产品分配等级的函数:
SELECT
product_id,
product_name,
price,
RANK () OVER (
ORDER BY price DESC
) price_rank
FROM
products;
输出:
相关用法
- PostgreSQL ARRAY_AGG()用法及代码示例
- PostgreSQL AVG()用法及代码示例
- PostgreSQL COUNT()用法及代码示例
- PostgreSQL STRING_AGG()用法及代码示例
- PostgreSQL MAX()用法及代码示例
- PostgreSQL MIN()用法及代码示例
- PostgreSQL SUM()用法及代码示例
- PostgreSQL DENSE_RANK用法及代码示例
- PostgreSQL NULLIF()用法及代码示例
- PostgreSQL Drop用法及代码示例
- PostgreSQL FIRST_VALUE用法及代码示例
- PostgreSQL LAST_VALUE用法及代码示例
- PostgreSQL LEAD用法及代码示例
- PostgreSQL NTILE用法及代码示例
- PostgreSQL CUME_DIST用法及代码示例
注:本文由纯净天空筛选整理自RajuKumar19大神的英文原创作品 PostgreSQL – RANK Function。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。