在數據分析和統計方麵,Python是一種非常流行的語言。幸運的是,Python3提供了統計模塊,它帶有非常有用的函數,例如mean(), median(), mode()等等
統計模塊中的median()函數可用於從未排序的data-list計算中值。使用median()函數的最大優點是,在將data-list作為參數發送給median()函數之前,無需對其進行排序。
中位數是將數據樣本或概率分布的上半部分與下半部分分開的值。對於數據集,可以將其視為中間值。中位數是統計和概率論中data-set屬性的集中趨勢的度量。中值相對於均值具有很大的優勢,因為中值不會因太大或很小的值而有太大的偏差。中間值包含在提供的值的data-set中,或者與提供的數據相差不大。
對於奇數個元素集,中間值是中間值。對於偶數元素集,中值是兩個中間元素的平均值。
Median can be represented by the following formula:
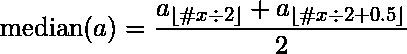
用法:
median([data-set])參數:
[data-set]:列表或元組或帶有一組數字的可迭代
返回:返回包含數據的可迭代對象的中位數(中間值)
Exceptions: StatisticsError當iterable通過為空或list為null時引發。
代碼1:工作中
# Python code to demonstrate the
# working of median() function.
# importing statistics module
import statistics
# unsorted list of random integers
data1 = [2, -2, 3, 6, 9, 4, 5, -1]
# Printing median of the
# random data-set
print("Median of data-set is:% s "
% (statistics.median(data1)))輸出:
Median of data-set is:3.5
代碼2:
# Python code to demonstrate the
# working of median() on various
# range of data-sets
# importing the statistics module
from statistics import median
# Importing fractions module as fr
from fractions import Fraction as fr
# tuple of positive integer numbers
data1 = (2, 3, 4, 5, 7, 9, 11)
# tuple of floating point values
data2 = (2.4, 5.1, 6.7, 8.9)
# tuple of fractional numbers
data3 = (fr(1, 2), fr(44, 12),
fr(10, 3), fr(2, 3))
# tuple of a set of negative integers
data4 = (-5, -1, -12, -19, -3)
# tuple of set of positive
# and negative integers
data5 = (-1, -2, -3, -4, 4, 3, 2, 1)
# Printing the median of above datsets
print("Median of data-set 1 is % s" % (median(data1)))
print("Median of data-set 2 is % s" % (median(data2)))
print("Median of data-set 3 is % s" % (median(data3)))
print("Median of data-set 4 is % s" % (median(data4)))
print("Median of data-set 5 is % s" % (median(data5)))輸出:
Median of data-set 1 is 5 Median of data-set 2 is 5.9 Median of data-set 3 is 2 Median of data-set 4 is -5 Median of data-set 5 is 0.0
代碼3:展示StatisticsError
# Python code to demonstrate
# StatisticsError of median()
# importing the statistics module
from statistics import median
# creating an empty data-set
empty = []
# will raise StatisticsError
print(median(empty))輸出:
Traceback (most recent call last):
File "/home/3c98774036f97845ee9f65f6d3571e49.py", line 12, in
print(median(empty))
File "/usr/lib/python3.5/statistics.py", line 353, in median
raise StatisticsError("no median for empty data")
statistics.StatisticsError:no median for empty data
應用範圍:
對於實際應用,根據可以估計相應人口值的程度比較比較分散和人口趨勢的不同度量。例如,比較顯示,當數據不受重尾數據分布或數據分布混合的數據汙染時,樣本均值比樣本中位數在統計上更有效,但在其他方麵效率較低,並且樣本中位數為高於各種發行版。更具體地說,與minimum-variance-mean(對於大型正常樣本)相比,中位數效率為64%。
相關用法
- Python statistics median_low()用法及代碼示例
- Python statistics median_high()用法及代碼示例
- Python statistics median_grouped()用法及代碼示例
- Python - statistics stdev()用法及代碼示例
- Python statistics variance()用法及代碼示例
- Python statistics pvariance()用法及代碼示例
- Python statistics mean()用法及代碼示例
- Python statistics harmonic_mean()用法及代碼示例
注:本文由純淨天空篩選整理自retr0大神的英文原創作品 Python statistics | median()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。