Pandas DataFrame.merge(~) 方法將源 DataFrame 與另一個 DataFrame 或命名係列合並。
參數
1.right | DataFrame 或 named Series
要合並源 DataFrame 的 DataFrame 或係列。
2. how | string | optional
要執行的合並類型:
|
值 |
說明 |
|---|---|
|
源 DataFrame 中的所有行都將出現在生成的 DataFrame 中。這相當於 left-join 的 SQL。 | |
|
右側 DataFrame 中的所有行都將出現在生成的 DataFrame 中。這相當於 right-join 的 SQL。 | |
|
來自源和右側 DataFrame 的所有行都將出現在生成的 DataFrame 中。這相當於 outer-join 的 SQL。 | |
|
在源 DataFrame 中具有匹配值的所有行都將出現在生成的 DataFrame 中。這是相當於 inner-join 的 SQL。 |
默認情況下,how="inner" 。
這是說明差異的經典維恩圖:
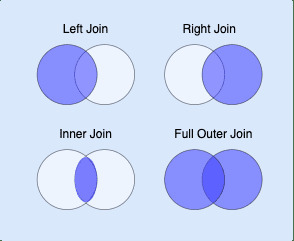
3. on | string 或 list | optional
要執行連接的列或 index-levels 的標簽。僅當左側和右側 DataFrames 具有相同標簽時才有效。默認情況下, on=None ,這意味著將執行內部聯接。
注意
on 參數隻是為了方便起見。如果要連接的列具有不同的標簽,則必須使用 left_on 、 right_on 、 left_index 和 right_index 代替。
4. left_on | string 或 array-like | optional
要執行連接的左側 DataFrame 的列標簽或索引級別。
5. right_on | string 或 array-like | optional
要執行連接的右側 DataFrame 的列標簽或索引級別。
6. left_index | boolean | optional
是否對左側 DataFrame 的索引執行連接。默認情況下,left_index=False 。
7. right_index | boolean | optional
是否對右側 DataFrame 的索引執行連接。默認情況下,right_index=False 。
注意
許多教科書和文檔都使用這些詞合並鍵或者連接鍵表示執行連接的列。
8. sort | boolean | optional
是否根據連接鍵對行進行排序。默認情況下,sort=False 。
9. suffixes | (string, string) 的tuple | optional
要附加到生成的 DataFrame 中的重複列標簽的後綴名稱。默認情況下,suffixes=("_x", "_y") 。
10.copy | boolean | optional
-
如果
True,則返回 DataFrame 的新副本。 -
如果是
False,則盡可能避免創建新副本。
默認情況下,copy=True 。
11.indicator | boolean 或 string | optional
是否添加一個名為 _merge 的額外列,它告訴我們該行是從哪個 DataFrame 構造的。默認情況下,indicator=False 。
12.validate | string | optional
要運行的驗證邏輯:
|
值 |
說明 |
|---|---|
|
|
檢查左右合並鍵是否唯一。 |
|
|
檢查左側的合並鍵是否唯一。 |
|
|
檢查右側的合並鍵是否唯一。 |
|
|
不執行任何檢查。 |
默認情況下,validate=None 。
返回值
合並的 DataFrame。
例子
執行inner-join
假設一個店主有以下數據:
|
ID |
產品 |
bought_by |
|---|---|---|
|
A |
computer |
1 |
|
B |
smartphone |
3 |
|
C |
headphones |
NaN |
|
ID |
名字 |
年齡 |
|---|---|---|
|
1 |
alex |
10 |
|
2 |
bob |
20 |
|
3 |
cathy |
30 |
在這裏,頂部表格是關於商店擁有的產品,而底部表格是關於注冊客戶的資料。
假設我們想查看購買了產品的客戶的個人資料。為此,我們需要對 products 表的 bought_by 列和 customers 表的索引標簽執行內部聯接。
首先,讓我們創建兩個 DataFrame。這是products 數據幀:
df_products = pd.DataFrame({"product": ["computer", "smartphone", "headphones"],
"bought_by": [1, 3, pd.np.NaN]},
index=["A","B","C"])
df_products
product bought_by
A computer 1.0
B smartphone 3.0
C headphones NaN這是customers 數據幀:
df_customers = pd.DataFrame({"name": ["alex", "bob", "cathy"],
"age": [10, 20, 30]},
index=[1,2,3])
df_customers
name age
1 alex 10
2 bob 20
3 cathy 30現在,執行inner-join:
df_products.merge(df_customers, how="inner", left_on="bought_by", right_index=True)
product bought_by name age
A computer 1.0 alex 10
B smartphone 3.0 cathy 30請注意以下事項:
-
left_on="bought_by"表示我們要使用左側 DataFrame 的bought_by列進行對齊。 -
right_index=True表示我們要使用右側 DataFrame 的索引進行對齊。我們還可以通過指定right_on參數來基於列進行合並。 -
您可以在此處省略
how參數,因為默認值為"inner"。 -
請注意列的順序 - 源 DataFrame 的列(即
df_products)首先出現,然後是正確 DataFrame 的列。
執行left-join
為了演示left-join,我們將使用與之前相同的產品和客戶示例:
[df_products] | [df_customers]
product bought_by | name age
A computer 1.0 | 1 alex 10
B smartphone 3.0 | 2 bob 20
C headphones NaN | 3 cathy 30要查看所有產品以及購買該產品的客戶的個人資料,我們需要執行left-join,如下所示:
df_products.merge(df_customers, how="left", left_on="bought_by", right_index=True)
product bought_by name age
A computer 1.0 alex 10.0
B smartphone 3.0 cathy 30.0
C headphones NaN NaN NaN-
left_on="bought_by"表示我們要使用左側 DataFrame 的bought_by列進行對齊。 -
right_index=True表示我們要使用右側 DataFrame 的索引進行對齊。 -
請注意列的順序 - 源 DataFrame 的列(即
df_products)首先出現,然後是正確 DataFrame 的列。
執行right-join
為了演示right-join,我們將使用與之前相同的產品和客戶示例:
[df_products] | [df_customers]
product bought_by | name age
A computer 1.0 | 1 alex 10
B smartphone 3.0 | 2 bob 20
C headphones NaN | 3 cathy 30要查看所有客戶的個人資料以及他們購買的產品,我們需要執行right-join,如下所示:
df_products.merge(df_customers, how="right", left_on="bought_by", right_index=True)
product bought_by name age
A computer 1.0 alex 10
B smartphone 3.0 cathy 30
NaN NaN 2.0 bob 20執行full-join
為了演示full-join,我們將使用與之前相同的產品和客戶示例:
[df_products] | [df_customers]
product bought_by | name age
A computer 1.0 | 1 alex 10
B smartphone 3.0 | 2 bob 20
C headphones NaN | 3 cathy 30要查看所有客戶以及所有產品的資料,我們需要執行full-join,如下所示:
df_products.merge(df_customers, how="outer", left_on="bought_by", right_index=True)
product bought_by name age
A computer 1.0 alex 10.0
B smartphone 3.0 cathy 30.0
C headphones NaN NaN NaN
NaN NaN 2.0 bob 20.0指定排序參數
為了演示 sort 參數的作用,我們將使用與之前相同的產品和客戶示例:
[df_products] | [df_customers]
product bought_by | name age
A computer 3.0 | 1 alex 10
B smartphone 1.0 | 2 bob 20
C headphones NaN | 3 cathy 30附帶說明一下,bought_by 列中的值的順序已交換,因為這將使我們能夠看到 sort=True 的行為。
假設我們執行了left-join,如下所示:
df_products.merge(df_customers, how="left", left_on="bought_by", right_index=True, sort=True)
product bought_by name age
B smartphone 1.0 alex 10.0
A computer 3.0 cathy 30.0
C headphones NaN NaN NaN請注意生成的 DataFrame 如何根據連接鍵(bought_by 列)進行排序。如果沒有 sort=True ,該列將不會被排序,即,將保留原始順序。
指定後綴參數
為了演示 suffix 參數的作用,我們將使用與之前相同的產品和客戶示例:
[df_products] | [df_customers]
name bought_by | name age
A computer 1.0 | 1 alex 10
B smartphone 3.0 | 2 bob 20
C headphones NaN | 3 cathy 30請注意,之前我們使用列標簽 product 作為產品名稱,但在本例中,我們將使用列標簽 name。現在,我們的列名稱有重疊。
要了解 Pandas 默認情況下如何處理此問題,讓我們執行inner-join:
df_products.merge(df_customers, how="inner", left_on="bought_by", right_index=True)
name_x bought_by name_y age
A computer 1.0 alex 10
B smartphone 3.0 cathy 30我們看到 Pandas 添加了後綴 _x 和 _y 來區分列。
我們可以通過指定 suffixes 參數來覆蓋此行為,該參數僅接受後綴元組:
df_products.merge(df_customers, how="inner", left_on="bought_by", right_index=True, suffixes=("_product", "_customer"))
name_product bought_by name_customer age
A computer 1.0 alex 10
B smartphone 3.0 cathy 30觀察列名現在如何反映我們指定的後綴。
指定指標參數
為了演示 indicator 參數的作用,我們將使用與之前相同的產品和客戶示例:
[df_products] | [df_customers]
product bought_by | name age
A computer 1.0 | 1 alex 10
B smartphone 3.0 | 2 bob 20
C headphones NaN | 3 cathy 30假設我們使用 indicator=True 執行左連接:
df_products.merge(df_customers, how="left", left_on="bought_by", right_index=True, indicator=True)
product bought_by name age _merge
A computer 1.0 alex 10.0 both
B smartphone 3.0 cathy 30.0 both
C headphones NaN NaN NaN left_only請注意以下事項:
-
請注意我們如何在末尾添加一個名為
_merge的附加列。此列告訴我們該行是由哪個 DataFrame 構造的。 -
前兩行的值為
"both",這意味著在源 DataFrame 和rightDataFrame 中都找到了匹配項。通過回顧我們的兩個 DataFrame,您可以輕鬆確認這是True。 -
最後一行的值為
"left_only",這意味著該行來自源 DataFrame。
指定驗證參數
我們將再次使用有關產品和客戶的相同示例:
[df_products] | [df_customers]
product bought_by | name age
A computer 1.0 | 1 alex 10
B smartphone 3.0 | 2 bob 20
C headphones 3.0 | 3 cathy 30在此示例中,我們將耳機的 "bought_by" 值從 NaN 更改為 3 。
讓我們對客戶 ID 執行inner-join:
df_products.merge(df_customers, how="inner", right_index=True, left_on="bought_by")
product bought_by name age
A computer 3 cathy 30
C headphones 3 cathy 30
B smartphone 1 alex 10這裏,一位客戶 (Cathy) 購買了 2 件產品,因此這是一個 1:2 映射,通常寫為 1:m,其中 m 隻代表大於 1 的數字。
現在讓我們調用完全相同的函數,但使用 validate="1:1" :
df_products.merge(df_customers, how="inner", right_index=True, left_on="bought_by", validate="1:1")
MergeError: Merge keys are not unique in left dataset; not a one-to-one merge由於這不是 1:1 映射,因此會引發錯誤。更一般地說,如果左側 DataFrame 具有重複值,則驗證規則 "1:1" 和 "1:m" 將引發錯誤。
相關用法
- Python Pandas DataFrame mean方法用法及代碼示例
- Python Pandas DataFrame memory_usage方法用法及代碼示例
- Python Pandas DataFrame melt方法用法及代碼示例
- Python Pandas DataFrame median方法用法及代碼示例
- Python Pandas DataFrame max方法用法及代碼示例
- Python Pandas DataFrame mod方法用法及代碼示例
- Python Pandas DataFrame mode方法用法及代碼示例
- Python Pandas DataFrame mask方法用法及代碼示例
- Python Pandas DataFrame min方法用法及代碼示例
- Python Pandas DataFrame mad方法用法及代碼示例
- Python Pandas DataFrame mul方法用法及代碼示例
- Python Pandas DataFrame empty屬性用法及代碼示例
- Python Pandas DataFrame pop方法用法及代碼示例
- Python Pandas DataFrame nsmallest方法用法及代碼示例
- Python Pandas DataFrame sample方法用法及代碼示例
- Python Pandas DataFrame items方法用法及代碼示例
- Python Pandas DataFrame swaplevel方法用法及代碼示例
- Python Pandas DataFrame agg方法用法及代碼示例
- Python Pandas DataFrame copy方法用法及代碼示例
- Python Pandas DataFrame pow方法用法及代碼示例
- Python Pandas DataFrame insert方法用法及代碼示例
- Python Pandas DataFrame lt方法用法及代碼示例
- Python Pandas DataFrame all方法用法及代碼示例
- Python Pandas DataFrame unstack方法用法及代碼示例
- Python PySpark DataFrame filter方法用法及代碼示例
注:本文由純淨天空篩選整理自Isshin Inada大神的英文原創作品 Pandas DataFrame | merge method。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。