用法:
RandomState.zipf(a, size=None)從Zipf分布中抽取樣本。
樣本是從Zipf分布中提取的,其中指定參數a> 1。
Zipf分布(也稱為zeta分布)是滿足Zipf定律的連續概率分布:項目的頻率與其在頻率表中的排名成反比。
參數: - a: : float 或 array_like of floats
分布參數。必須大於1。
- size: : int 或 tuple of ints, 可選參數
輸出形狀。如果給定的形狀是
(m, n, k), 然後m * n * k抽取樣品。如果尺寸是None(默認),如果返回一個值a是標量。除此以外,np.array(a).size抽取樣品。
返回值: - out: : ndarray或標量
從參數化的Zipf分布中抽取樣本。
注意:
Zipf分布的概率密度為

哪裏
 是黎曼Zeta函數。
是黎曼Zeta函數。它以美國語言學家喬治·金斯利·齊普夫(George Kingsley Zipf)的名字命名,他指出,一種語言樣本中任何單詞的出現頻率均與其在頻率表中的排名成反比。
參考文獻:
[1] Zipf,G. K.,“語言中相對頻率原理的精選研究”,麻省劍橋:哈佛大學。出版社,1932年。 例子:
從分布中抽取樣本:
>>> a = 2. # parameter >>> s = np.random.zipf(a, 1000)顯示樣本的直方圖以及概率密度函數:
>>> import matplotlib.pyplot as plt >>> from scipy import special # doctest:+SKIP在50處截斷s值,因此繪圖很有趣:
>>> count, bins, ignored = plt.hist(s[s<50], 50, density=True) >>> x = np.arange(1., 50.) >>> y = x**(-a) / special.zetac(a) # doctest:+SKIP >>> plt.plot(x, y/max(y), linewidth=2, color='r') # doctest:+SKIP >>> plt.show()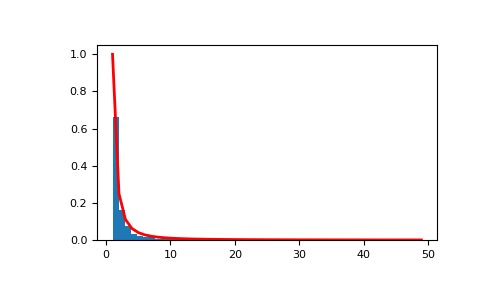
相關用法
注:本文由純淨天空篩選整理自 numpy.random.mtrand.RandomState.zipf。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。