Hadoop的優勢在於批處理,MapReduce並不特別適用於交互/特殊指定的查詢。 實時(Real-time)1SQL查詢(在Hadoop數據上)通常使用自定義連接器來執行MPP數據庫。實際上這意味著在獨立的Hadoop和數據庫集群之間有連接器。在過去幾個月中,一些提供快速的係統Hadoop集群中的SQL訪問受到關注。 Hadoop和快速MPP數據庫集群之間的連接器並沒有消失,但是人們越來越感興趣於將許多交互式SQL任務轉移到與Hadoop共存於同一集群上的係統中。
擁有支持快速/交互式SQL查詢的Hadoop集群可以追溯到幾年前HadoopDB,一個來自耶魯的開源項目。 HadoopDB的創建者此後開始了一家商業軟件公司(Hadapt),旨在構建一個將Hadoop /MapReduce和SQL相結合的係統。在Hadapt中,(Postgres)數據庫放置在Hadoop集群的節點中,形成一個係統2可以使用MapReduce、SQL和搜索(Solr)。從版本2.0開始,Hadapt是容錯係統,具有分析功能(HDK),可以通過SQL使用。
開源係統
本文的其餘部分介紹了兩個相對較新的開源工具:Impala和Shark。
自Strata NYC發布以來,Cloudera的Impala係統產生的嗡嗡聲突出顯示了大數據社區需要Hadoop中的實時查詢係統的程度。自從發布以來,已經有許多關於Impala的優秀文章(參見這裏和這裏),所以這裏不會深入涉及它的設計細節。我會強調一下Cloudera展現的令人印象深刻的性能數據。
對於純粹的I/O綁定查詢,我們通常會看到3-4倍範圍內的性能提升。 …對於至少有一次連接的查詢,我們已經看到7-45X的性能提升。 …如果通過查詢訪問的數據從緩存中提取出來,由於Impala的卓越效率,加速將更加激烈。在這些情況下,即使在簡單的聚合查詢中,我們也看到了Hive上20倍-90倍的加速。
Shark
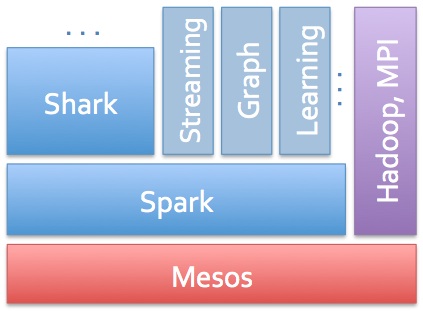
Shark是一個Spark組件,一個開源的分布式和容錯內存分析係統,可以安裝在與Hadoop相同的集群上。特別是,Shark完全兼容Hive和支持HiveQL,Hive數據格式和用戶自定義功能。另外Shark可以用來查詢來自4在HDFS,HBase和Amazon S3的數據。
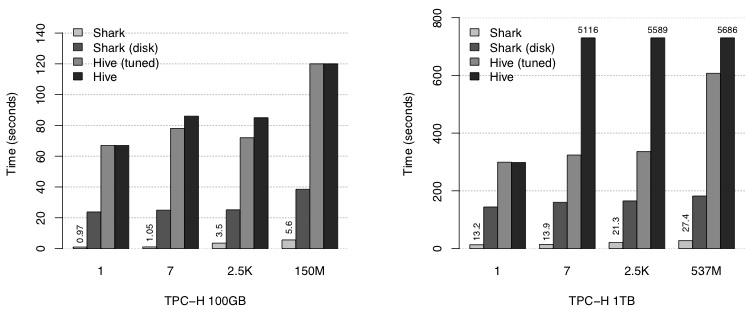
Shark的創作者剛剛發表了一篇論文,在文中他們係統地比較了它與Hive的表現,Hadoop和MPP數據庫。他們發現Shark比Hive在各種查詢上快得多:大概來說,Shark在磁盤上的速度要快5-10倍,而Shark內存模式的速度要快100倍。重要的是,Shark的表現收益是與MPP數據庫中觀察到的相當!
在這個階段,用戶至少有兩個可用於Hadoop中快速/交互式SQL的開源係統。雖然Impala引起了更多的關注,但Shark團隊已悄悄地將高擴展係統集成在一起,該係統具有引人注目的功能五包括數據聯合分區(co-partitioning),容錯(fault-tolerance)以及將機器學習(machine-learning)集成到分析師的工作流程中。
內存列存儲和列壓縮
使用Impala時獲得的最佳性能是通過使用Trevni列存儲格式實現的。在Shark的情況下,他們的自定義列式存儲和壓縮將存儲和查詢時間縮短了大約5倍。
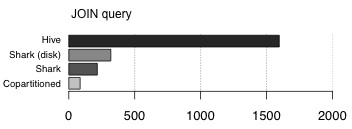
控製數據分區=>快速,分散式JOINS
Shark讓用戶使用指定的鍵分區表。特別是如果表經常是“joined”,那麽可以使用通用(“join”)鍵對它們進行分區。 Co-partitioning是許多MPP數據庫用來加速“joins”涉及大量表的技巧。
容錯(Fault-tolerance)
Shark可以從節點故障中優雅地恢複6,並且在重建丟失的(數據)分區之後繼續執行查詢。對大數據集的初始測試表明恢複對性能的影響很小(並且比re-executing查詢快得多)。
SQL “optimizer”
Shark已經實現了一個簡單的優化器(部分DAG執行或PDE)使用數據統計(重擊者,近似直方圖)在需要時動態地改變查詢計劃。例如,Shark的PDE係統使用數據統計信息為“joins”執行run-time優化。
機器學習(Machine-learning)支持
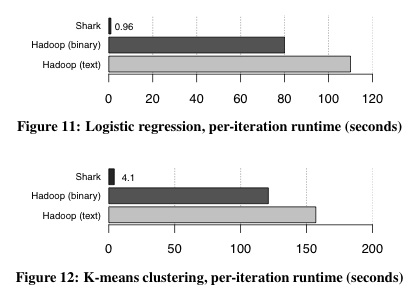
RDD的是分散式可以緩存在跨計算節點集群內存中的對象。它們是Spark中使用的基本數據對象。用戶可以創建RDD(使用sql2rdd命令)並將machine-learning函數應用於它們。目前machine-learning和分析函數可以用Scala和Java編寫,並且即將支持Python。用戶不僅可以從相同的內部獲得執行簡單SQL查詢和複雜計算的好處7框架,而且Shark比Hadoop快100倍:
與BI工具集成
Impala與Tableau和QlikView的。有Shark用戶使用Tableau之類的工具,但BI集成是Shark內的相對未探索(“unexplored”)區域。
總結
Impala和Shark是Hadoop的交互式SQL係統。一個新文章顯示Shark提供加速與MPP數據庫中觀察到的相當。除了比Hive for SQL快100倍以外,Shark的框架比(迭代式)machine-learning算法的Hadoop快100倍。
如果你想了解更多關於Shark/Spark的信息,請點擊這裏Amplab團隊正在提供一個教程(2013年地層會議在聖克拉拉)。