原文標題:Anatomy of a Program in Memory
原文地址:http://duartes.org/gustavo/blog/ [注:本人水平有限,隻好挑一些國外高手的精彩文章翻譯一下。一來自己複習,二來與大家分享。]
內存管理模塊是操作係統的心髒;它對應用程序和係統管理非常重要。今後的幾篇文章中,我將著眼於實際的內存問題,但也不避諱其中的技術內幕。由於不少概念 是通用的,所以文中大部分例子取自32位x86平台的Linux和Windows係統。本係列第一篇文章講述應用程序的內存布局。
在多任務操作係統中的每一個進程都運行在一個屬於它自己的內存沙盤中。這個沙盤就是虛擬地址空間(virtual address space),在32位模式下它總是一個4GB的內存地址塊。這些虛擬地址通過頁表(page table)映射到物理內存,頁表由操作係統維護並被處理器引用。每一個進程擁有一套屬於它自己的頁表,但是還有一個隱情。隻要虛擬地址被使能,那麽它就 會作用於這台機器上運行的所有軟件,包括內核本身。因此一部分虛擬地址必須保留給內核使用:
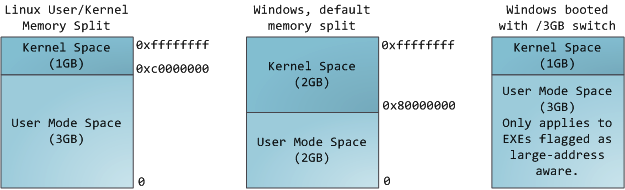
這並不意味著內核使用了那麽多的物理內存,僅表示它可支配這麽大的地址空間,可根據內核需要,將其映射到物理內存。內核空間在頁表中擁有較高的特權級 (ring 2或以下),因此隻要用戶態的程序試圖訪問這些頁,就會導致一個頁錯誤(page fault)。在Linux中,內核空間是持續存在的,並且在所有進程中都映射到同樣的物理內存。內核代碼和數據總是可尋址的,隨時準備處理中斷和係統調 用。與此相反,用戶模式地址空間的映射隨進程切換的發生而不斷變化:
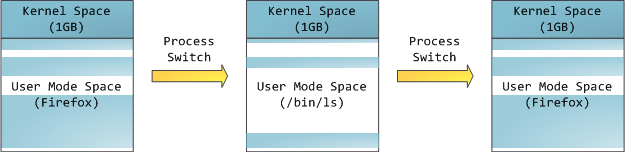
藍色區域表示映射到物理內存的虛擬地址,而白色區域表示未映射的部分。在上麵的例子中,Firefox使用了相當多的虛擬地址空間,因為它是傳說中的吃內 存大戶。地址空間中的各個條帶對應於不同的內存段(memory segment),如:堆、棧之類的。記住,這些段隻是簡單的內存地址範圍,與Intel處理器的段沒有關係。不管怎樣,下麵是一個Linux進程的標準 的內存段布局:
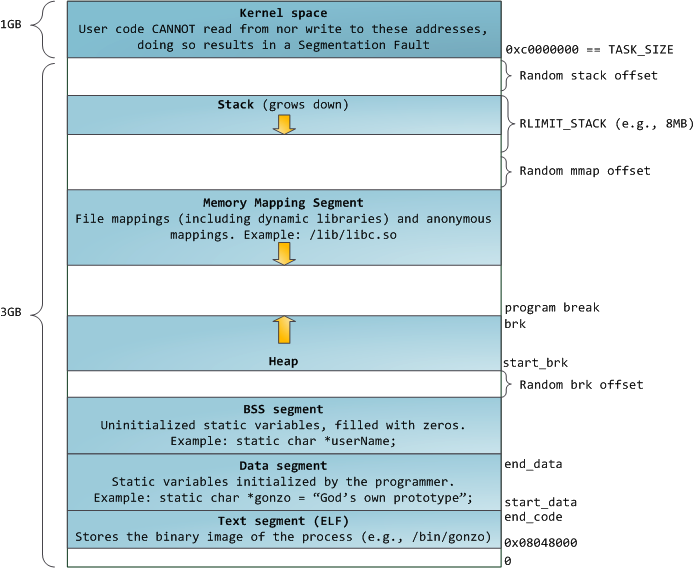
當計算機開心、安全、可愛、正常的運轉時,幾乎每一個進程的各個段的起始虛擬地址都與上圖完全一致,這也給遠程發掘程序安全漏洞打開了方便之門。一 個發掘過程往往需要引用絕對內存地址:棧地址,庫函數地址等。遠程攻擊者必須依賴地址空間布局的一致性,摸索著選擇這些地址。如果讓他們猜個正著,有人就 會被整了。因此,地址空間的隨機排布方式逐漸流行起來。Linux通過對棧、內存映射段、堆的起始地址加上隨機的偏移量來打亂布局。不幸的是,32位地址 空間相當緊湊,給隨機化所留下的空當不大,削弱了這種技巧的效果。
進程地址空間中最頂部的段是棧,大多數編程語言將之用於存儲局部變量和函數參數。調用一個方法或函數會將一個新的棧楨(stack frame)壓入棧中。棧楨在函數返回時被清理。也許是因為數據嚴格的遵從LIFO的順序,這個簡單的設計意味著不必使用複雜的數據結構來追蹤棧的內容, 隻需要一個簡單的指針指向棧的頂端即可。因此壓棧(pushing)和退棧(popping)過程非常迅速、準確。另外,持續的重用棧空間有助於使活躍的 棧內存保持在CPU緩存中,從而加速訪問。進程中的每一個線程都有屬於自己的棧。
通過不斷向棧中壓入的數據,超出其容量就有會耗盡棧所對應的內存區域。這將觸發一個頁故障(page fault),並被Linux的expand_stack()處理,它會調用acct_stack_growth()來檢查是否還有合適的地方用於棧的增 長。如果棧的大小低於RLIMIT_STACK(通常是8MB),那麽一般情況下棧會被加長,程序繼續愉快的運行,感覺不到發生了什麽事情。這是一種將棧 擴展至所需大小的常規機製。然而,如果達到了最大的棧空間大小,就會棧溢出(stack overflow),程序收到一個段錯誤(Segmentation Fault)。當映射了的棧區域擴展到所需的大小後,它就不會再收縮回去,即使棧不那麽滿了。這就好比聯邦預算,它總是在增長的。
動態棧增長是唯一一種訪問未映射內存區域(圖中白色區域)而被允許的情形。其它任何對未映射內存區域的訪問都會觸發頁故障,從而導致段錯誤。一些被映射的區域是隻讀的,因此企圖寫這些區域也會導致段錯誤。
在棧的下方,是我們的內存映射段。此處,內核將文件的內容直接映射到內存。任何應用程序都可以通過Linux的mmap()係統調用(實現)或 Windows的CreateFileMapping() / MapViewOfFile()請求這種映射。內存映射是一種方便高效的文件I/O方式,所以它被用於加載動態庫。創建一個不對應於任何文件的匿名內存映 射也是可能的,此方法用於存放程序的數據。在Linux中,如果你通過malloc()請求一大塊內存,C運行庫將會創建這樣一個匿名映射而不是使用堆內 存。‘大塊’意味著比MMAP_THRESHOLD還大,缺省是128KB,可以通過mallopt()調整。
說到堆,它是接下來的一塊地址空間。與棧一樣,堆用於運行時內存分配;但不同點是,堆用於存儲那些生存期與函數調用無關的數據。大部分語言都提供了堆管理 功能。因此,滿足內存請求就成了語言運行時庫及內核共同的任務。在C語言中,堆分配的接口是malloc()係列函數,而在具有垃圾收集功能的語言(如 C#)中,此接口是new關鍵字。
如果堆中有足夠的空間來滿足內存請求,它就可以被語言運行時庫處理而不需要內核參與。否則,堆會被擴大,通過brk()係統調用(實現)來分配請求所需的 內存塊。堆管理是很複雜的,需要精細的算法,應付我們程序中雜亂的分配模式,優化速度和內存使用效率。處理一個堆請求所需的時間會大幅度的變動。實時係統 通過特殊目的分配器來解決這個問題。堆也可能會變得零零碎碎,如下圖所示:

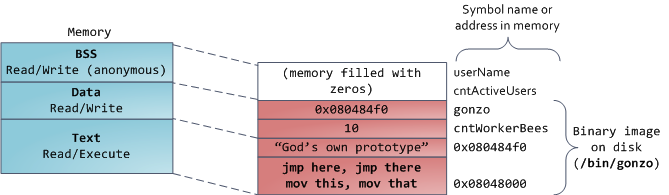
最後,我們來看看最底部的內存段:BSS,數據段,代碼段。在C語言中,BSS和數據段保存的都是靜態(全局)變量的內容。區別在於BSS保存的是 未被初始化的靜態變量內容,它們的值不是直接在程序的源代碼中設定的。BSS內存區域是匿名的:它不映射到任何文件。如果你寫static int cntActiveUsers,則cntActiveUsers的內容就會保存在BSS中。
另一方麵,數據段保存在源代碼中已經初始化了的靜態變量內容。這個內存區域不是匿名的。它映射了一部分的程序二進製鏡像,也就是源代碼中指定了初始值的靜 態變量。所以,如果你寫static int cntWorkerBees = 10,則cntWorkerBees的內容就保存在數據段中了,而且初始值為10。盡管數據段映射了一個文件,但它是一個私有內存映射,這意味著更改此處 的內存不會影響到被映射的文件。也必須如此,否則給全局變量賦值將會改動你硬盤上的二進製鏡像,這是不可想象的。
下圖中數據段的例子更加複雜,因為它用了一個指針。在此情況下,指針gonzo(4字節內存地址)本身的值保存在數據段中。而它所指向的實際字符串則不在 這裏。這個字符串保存在代碼段中,代碼段是隻讀的,保存了你全部的代碼外加零零碎碎的東西,比如字符串字麵值。代碼段將你的二進製文件也映射到了內存中, 但對此區域的寫操作都會使你的程序收到段錯誤。這有助於防範指針錯誤,雖然不像在C語言編程時就注意防範來得那麽有效。下圖展示了這些段以及我們例子中的 變量:
你可以通過閱讀文件/proc/pid_of_process/maps來檢驗一個Linux進程中的內存區域。記住一個段可能包含許多區域。比 如,每個內存映射文件在mmap段中都有屬於自己的區域,動態庫擁有類似BSS和數據段的額外區域。下一篇文章講說明這些“區域”(area)的真正含 義。有時人們提到“數據段”,指的就是全部的數據段 + BSS + 堆。
你可以通過nm和objdump命令來察看二進製鏡像,打印其中的符號,它們的地址,段等信息。最後需要指出的是,前文描述的虛擬地址布局在Linux中 是一種“靈活布局”(flexible layout),而且以此作為默認方式已經有些年頭了。它假設我們有值RLIMIT_STACK。當情況不是這樣時,Linux退回使用“經典布局” (classic layout),如下圖所示:

對虛擬地址空間的布局就講這些吧。下一篇文章將討論內核是如何跟蹤這些內存區域的。我們會分析內存映射,看看文件的讀寫操作是如何與之關聯的,以及內存使用概況的含義。
本文來自CSDN博客,轉載請標明出處:http://blog.csdn.net/drshenlei/archive/2009/07/11/4339110.aspx