step_impute_linear() 創建配方步驟的規範,該步驟將創建線性回歸模型來估算缺失數據。
用法
step_impute_linear(
recipe,
...,
role = NA,
trained = FALSE,
impute_with = imp_vars(all_predictors()),
models = NULL,
skip = FALSE,
id = rand_id("impute_linear")
)參數
- recipe
-
一個菜譜對象。該步驟將添加到此配方的操作序列中。
- ...
-
一個或多個選擇器函數來選擇要估算的變量;這些變量的類型必須是
numeric。當與imp_vars一起使用時,這些點指示哪些變量用於預測每個變量中的缺失數據。有關更多詳細信息,請參閱selections()。 - role
-
由於沒有創建新變量,因此此步驟未使用。
- trained
-
指示預處理數量是否已估計的邏輯。
- impute_with
-
調用
imp_vars來指定使用哪些變量來插補變量,這些變量可以包含由逗號或不同選擇器分隔的特定變量名稱(請參閱selections())。如果某個列同時包含在要插補的列表和插補預測變量的列表中,則該列將從後者中刪除,並且不會用於插補本身。 - models
- skip
-
一個合乎邏輯的。當
bake()烘焙食譜時是否應該跳過此步驟?雖然所有操作都是在prep()運行時烘焙的,但某些操作可能無法對新數據進行(例如處理結果變量)。使用skip = TRUE時應小心,因為它可能會影響後續操作的計算。 - id
-
該步驟特有的字符串,用於標識它。
細節
對於需要插補的每個變量,擬合線性模型,其中結果是感興趣的變量,預測變量是 impute_with 公式中列出的任何其他變量。請注意,如果要估算的變量也在 impute_with 中,則該變量將被忽略。
要估算的變量必須為 numeric 類型。估算值將保持與其原始數據相同的類型(即,模型預測根據需要強製為整數)。
由於這是線性回歸,插補模型僅使用訓練集預測變量的完整案例。
整理
當您tidy()此步驟時,將返回包含列terms(選擇的選擇器或變量)和model(袋裝樹對象)的tibble。
箱重
此步驟執行可以利用案例權重的無監督操作。因此,個案權重僅與頻率權重一起使用。有關更多信息,請參閱 case_weights 中的文檔和 tidymodels.org 中的示例。
參考
庫恩,M. 和約翰遜,K. (2013)。特征工程和選擇https://bookdown.org/max/FES/handling-missing-data.html
也可以看看
其他插補步驟: step_impute_bag() 、 step_impute_knn() 、 step_impute_lower() 、 step_impute_mean() 、 step_impute_median() 、 step_impute_mode() 、 step_impute_roll()
例子
data(ames, package = "modeldata")
set.seed(393)
ames_missing <- ames
ames_missing$Longitude[sample(1:nrow(ames), 200)] <- NA
imputed_ames <-
recipe(Sale_Price ~ ., data = ames_missing) %>%
step_impute_linear(
Longitude,
impute_with = imp_vars(Latitude, Neighborhood, MS_Zoning, Alley)
) %>%
prep(ames_missing)
imputed <-
bake(imputed_ames, new_data = ames_missing) %>%
dplyr::rename(imputed = Longitude) %>%
bind_cols(ames %>% dplyr::select(original = Longitude)) %>%
bind_cols(ames_missing %>% dplyr::select(Longitude)) %>%
dplyr::filter(is.na(Longitude))
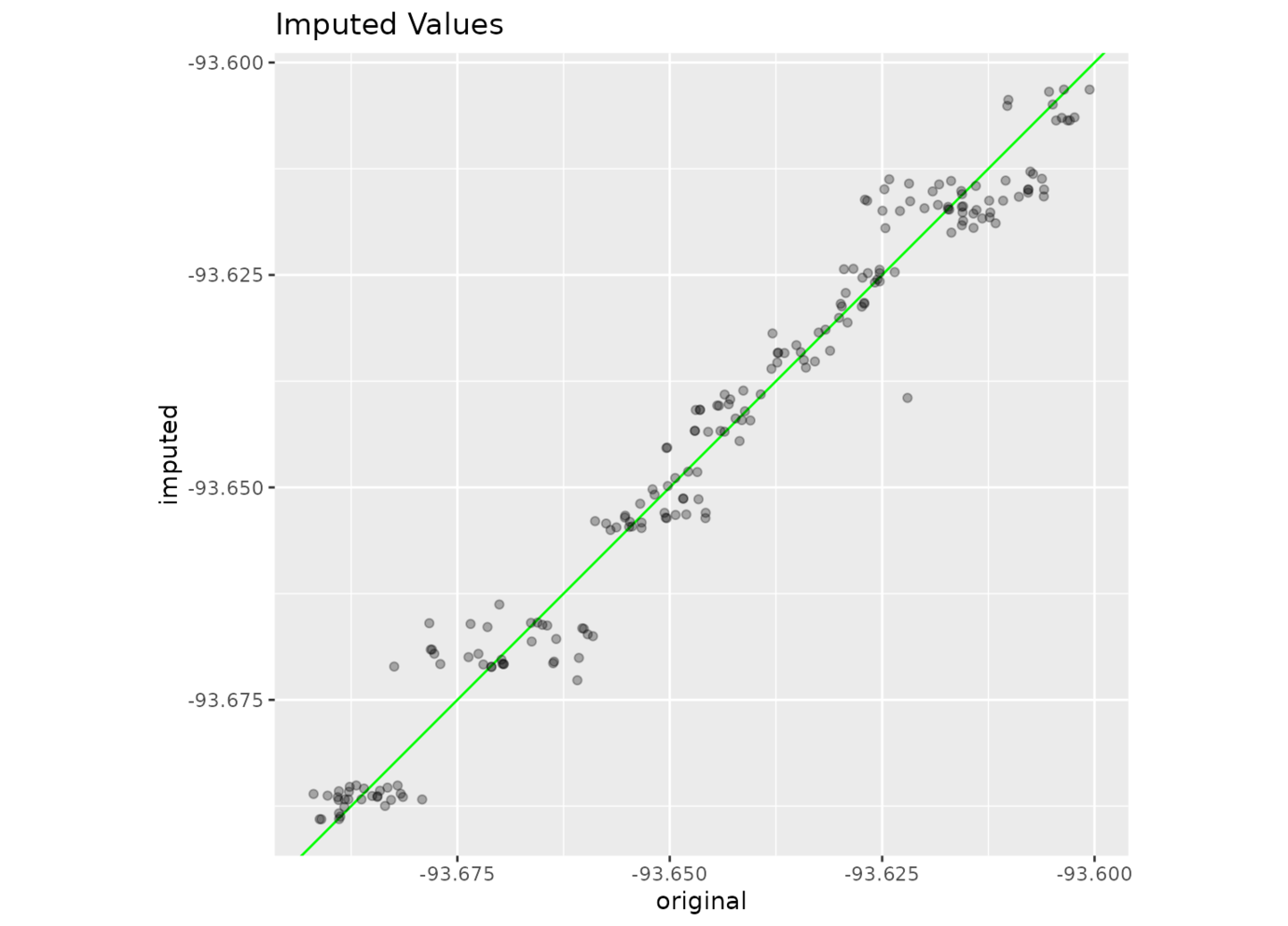
library(ggplot2)
ggplot(imputed, aes(x = original, y = imputed)) +
geom_abline(col = "green") +
geom_point(alpha = .3) +
coord_equal() +
labs(title = "Imputed Values")
相關用法
- R recipes step_impute_lower 估算低於測量閾值的數值數據
- R recipes step_impute_knn 通過 k 最近鄰進行插補
- R recipes step_impute_mean 使用平均值估算數值數據
- R recipes step_impute_roll 使用滾動窗口統計估算數值數據
- R recipes step_impute_mode 使用最常見的值估算名義數據
- R recipes step_impute_bag 通過袋裝樹進行插補
- R recipes step_impute_median 使用中位數估算數值數據
- R recipes step_inverse 逆變換
- R recipes step_ica ICA 信號提取
- R recipes step_indicate_na 創建缺失數據列指示器
- R recipes step_integer 將值轉換為預定義的整數
- R recipes step_intercept 添加截距(或常數)列
- R recipes step_interact 創建交互變量
- R recipes step_invlogit 逆 Logit 變換
- R recipes step_isomap 等位圖嵌入
- R recipes step_unknown 將缺失的類別分配給“未知”
- R recipes step_relu 應用(平滑)修正線性變換
- R recipes step_poly_bernstein 廣義伯恩斯坦多項式基
- R recipes step_pls 偏最小二乘特征提取
- R recipes step_ratio 比率變量創建
- R recipes step_geodist 兩個地點之間的距離
- R recipes step_nzv 近零方差濾波器
- R recipes step_nnmf 非負矩陣分解信號提取
- R recipes step_normalize 中心和比例數值數據
- R recipes step_depth 數據深度
注:本文由純淨天空篩選整理自Max Kuhn等大神的英文原創作品 Impute numeric variables via a linear model。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。