Python是進行數據分析的一種出色語言,主要是因為以數據為中心的Python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas 提供了一種獨特的方法來從 DataFrame 中檢索行。 DataFrame.loc []方法是僅使用索引標簽並在調用方數據幀中存在索引標簽的情況下返回行或數據幀的方法。
用法:pandas.DataFrame.loc[]
參數:
Index label:行的索引標簽的字符串或字符串列表
返回類型: DataFrame 或係列取決於參數
要下載代碼中使用的CSV,請點擊此處。
範例1:提取單行
在此示例中,將“名稱”列作為索引列,然後使用行的索引標簽以係列的形式一個接一個地提取兩個單行。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving row by loc method
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
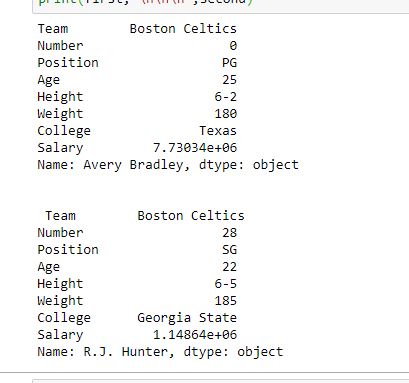
print(first, "\n\n\n", second)輸出:
如輸出圖像所示,由於兩次都隻有一個參數,因此返回了兩個係列。
範例2:多個參數
在此示例中,將“名稱”列作為索引列,然後通過將列表作為參數傳遞來同時提取兩個單行。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving rows by loc method
rows = data.loc[["Avery Bradley", "R.J. Hunter"]]
# checking data type of rows
print(type(rows))
# display
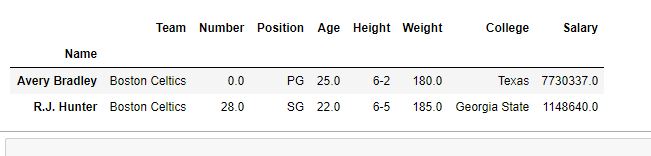
rows輸出:
如輸出圖像所示,這次返回值的數據類型為數據幀。兩行都被提取並像新 DataFrame 一樣顯示。
範例3:提取具有相同索引的多行
在此示例中,將團隊名稱作為索引列,並將一個團隊名稱傳遞到.loc方法以檢查是否已返回具有相同團隊名稱的所有值。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Team")
# retrieving rows by loc method
rows = data.loc["Utah Jazz"]
# checking data type of rows
print(type(rows))
# display
rows
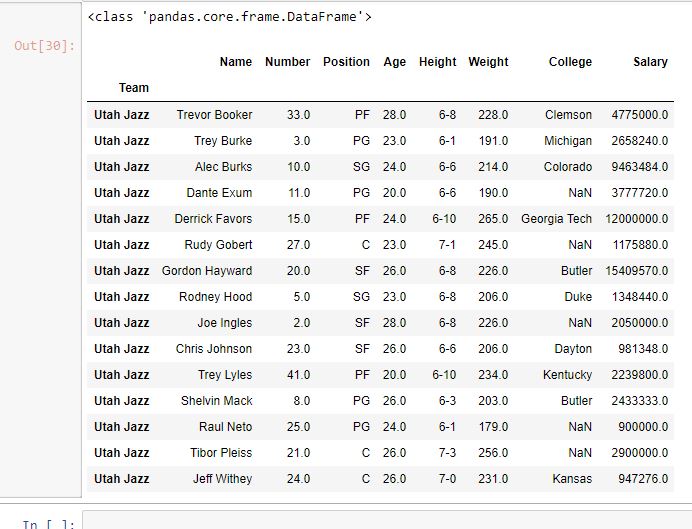
輸出:
如輸出圖像中所示,團隊名稱為“Utah Jazz”的所有行均以數據幀的形式返回。
範例4:提取兩個索引標簽之間的行
在此示例中,傳遞了行的兩個索引標簽,並且返回了位於這兩個索引標簽之間的所有行(兩個索引標簽均包括在內)。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving rows by loc method
rows = data.loc["Avery Bradley":"Isaiah Thomas"]
# checking data type of rows
print(type(rows))
# display
rows
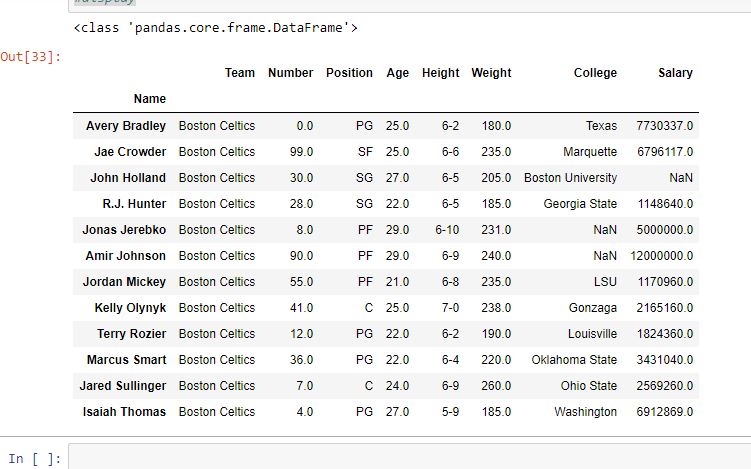
輸出:
如輸出圖像所示,位於傳遞的兩個索引標簽之間的所有行都以數據幀的形式返回。
相關用法
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Extracting rows using .loc[]。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。