用法:
RandomState.logseries(p, size=None)從對數級數分布中抽取樣本。
從具有指定形狀參數0 <的對數 Series 分布中抽取樣本
p<1。參數: - p: : float 或 array_like of floats
分布的形狀參數。必須在(0,1)範圍內。
- size: : int 或 tuple of ints, 可選參數
輸出形狀。如果給定的形狀是
(m, n, k), 然後m * n * k抽取樣品。如果尺寸是None(默認),如果返回一個值p是標量。除此以外,np.array(p).size抽取樣品。
返回值: - out: : ndarray或標量
從參數化對數級數分布中抽取樣本。
注意:
對數序列分布的概率密度為

其中p =概率。
對數級數分布通常用於表示物種的豐富度和發生率,最早由Fisher,Corbet和Williams於1943年提出[2]。它也可以用來模擬汽車中的乘員人數[3]。
參考文獻:
[1] 布薩斯(Martin A.); Culver,Stephen J.,通過事件的對數序列分布了解區域物種多樣性:生物多樣性研究多樣性與分布,第5卷,第5期,1999年9月,第187-195(9)頁。 [2] Fisher,R.A.,A.S. Corbet和C.B. Williams。 1943年。在動物種群的隨機樣本中,物種數量與個體數量之間的關係。動物生態學雜誌,12:42-58。 [3] D.J.Hand,F.Daly,D.Lunn,E.Ostrowski,《小數據集手冊》,CRC出版社,1994年。 [4] 維基百科,“Logarithmic distribution”,https://en.wikipedia.org/wiki/Logarithmic_distribution 例子:
從分布中抽取樣本:
>>> a = .6 >>> s = np.random.logseries(a, 10000) >>> import matplotlib.pyplot as plt >>> count, bins, ignored = plt.hist(s)#針對分布圖
>>> def logseries(k, p): ... return -p**k/(k*np.log(1-p)) >>> plt.plot(bins, logseries(bins, a)*count.max()/ ... logseries(bins, a).max(), 'r') >>> plt.show()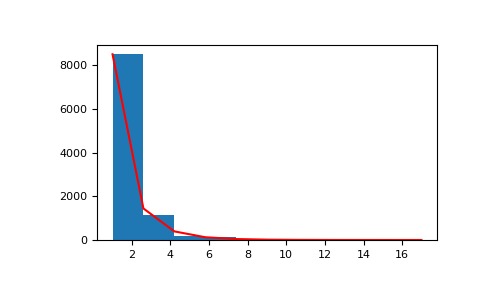
相關用法
注:本文由純淨天空篩選整理自 numpy.random.mtrand.RandomState.logseries。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。