此方法用於計算兩個(或更多個)因子的簡單cross-tabulation。默認情況下,除非傳遞值數組和聚合函數,否則將計算因子的頻率表。
用法:pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name=’All’, dropna=True, normalize=False)
Arguments:
- index:array-like,係列或數組/係列的列表,要在行中進行分組的值。
- columns:array-like,係列,或數組/係列的列表,要在列中分組的值。
- values:array-like,可選的值數組,根據因子進行匯總。要求指定`aggfunc`。
- rownames:序列,默認為無,如果傳遞,則必須與傳遞的行數組數匹配。
- colnames :sequence,默認為None,如果傳遞,則必須與傳遞的列數組數匹配。
- aggfunc:函數,可選,如果指定,則還需要指定`values`。
- margins:bool,默認為False,添加行/列邊距(小計)。
- margins_name:str,默認為“全部”,邊距為True時將包含總計的行/列的名稱。
- dropna:bool,默認為True,不包括所有條目均為NaN的列。
下麵是上述方法的實現和一些示例:
範例1:
Python3
# importing packages
import pandas
import numpy
# creating some data
a = numpy.array(["foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar",
"foo", "foo", "foo"],
dtype=object)
b = numpy.array(["one", "one", "one", "two",
"one", "one", "one", "two",
"two", "two", "one"],
dtype=object)
c = numpy.array(["dull", "dull", "shiny",
"dull", "dull", "shiny",
"shiny", "dull", "shiny",
"shiny", "shiny"],
dtype=object)
# form the cross tab
pandas.crosstab(a, [b, c], rownames=['a'], colnames=['b', 'c'])輸出:
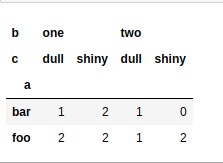
範例2:
Python3
# importing package
import pandas
# create some data
foo = pandas.Categorical(['a', 'b'],
categories=['a', 'b', 'c'])
bar = pandas.Categorical(['d', 'e'],
categories=['d', 'e', 'f'])
# form crosstab with dropna=True (default)
pandas.crosstab(foo, bar)
# form crosstab with dropna=False
pandas.crosstab(foo, bar, dropna=False)輸出:
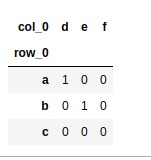
相關用法
- Python Wand function()用法及代碼示例
- Python Sorted()用法及代碼示例
- Python Numbers choice()用法及代碼示例
- Python Tkinter askopenfile()用法及代碼示例
- Python ord()用法及代碼示例
- Python sum()用法及代碼示例
- Python round()用法及代碼示例
- Python id()用法及代碼示例
- Python vars()用法及代碼示例
注:本文由純淨天空篩選整理自deepanshu_rustagi大神的英文原創作品 pandas.crosstab() function in Python。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。