本文由純淨的天空原創, 未經允許, 請勿轉載。
想在Wordpress中使用Markdown+Latex,如何設置?同時使用Markdown插件+Latex插件不就OK了嗎?
理想很完美,現實卻很骨感。之前baidu+google搜索查看了很多國內外相關資料,嘗試了各種插件或者修改Wordpress後台代碼,方案都或多或少有些問題,這裏親測實踐出了一套可行方案。
為什麽現有的方案有問題?
先說說直接Jetpack插件
Jetpack本身是可以直接支持Markdown+Latex的,網上有很多人說要用這個。如果是在國外,這個插件應該很好很強大,但是放到國內,問題就來了。首先網速就是個不可逾越的障礙,因為Jetpack的激活需要連接到國外雲服務器,注冊+日常操作經常會跟服務器交互,目前的速度累覺不愛。其次是,jetpack是很多的插件大集合,大部分功能我們的Wordpress網站並不一定需要,沒必要浪費資源。
獨立Markdown插件+Latex(MathJax)
WordPress中是Markdown先處理,然後再通過MathJax展示公式(JS或圖片兩種模式)。問題在於, Markdown語法跟Latex語法是有衝突的,比如:
下劃線”_”在Markdown中表示斜體,而在Latex中表示下標。Markdown先處理時”_”會被轉為為<em>或者<i>標簽,這樣等到Mathjax處理時,公式就亂了。
實踐可行的方案
第一步: 安裝Markdown on Save Improved插件, 再安裝LaTeX for WordPress插件,這兩個插件都可以在Wordpress後台直接安裝。
- Markdown on Save Improved簡潔可用,且在Wordpress中能兼容之前的非Markdown文章。
- Latex for WordPress插件依賴的Javascript等資源訪問比較慢,我們可以整個拷貝到Wordpress後台,然後做如下設置:
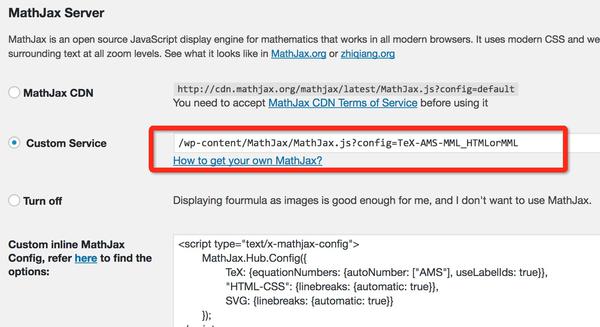
第二步: 安裝完上述插件之後,就可以成功使用Markdown了(注意禁用其他文本編輯插件),但是Latex公式有些問題。
- 分析Markdown on Save Improved的代碼可以發現,在markdown處理過程中,依次有stripslashes/transform/addslashes操作,這個會將Latex公式中的反斜杠”\”去掉,而這個正是Latex最常用的轉義符號。

- 另外就是Markdown語法跟Latex語法衝突的問題,比如下劃線”_”。
- 針對上述兩個問題,我們的解決方案是:先將Latex代碼段替換成某個特殊的字符串,等Markdown處理完再替換回來。具體操作為:將markdown-on-save.php中的函數
process修改為下列函數。
protected function process( $content, $id ){
return $this->processMarkdownWithLatex($content, $id);
/** 老代碼, markdown跟latex有衝突,所以重新實現了一個
$this->maybe_load_markdown();
// $content is slashed, but Markdown parser hates it precious.
$content = stripslashes( $content );
// convert to Markdown
$content = $this->parser->transform( $content );
// reference the post_id to make footnote ids unique
$content = preg_replace( '/fn(ref)?:/', "fn$1-$id:", $content );
// WordPress expects slashed data. Put needed ones back.
$content = addslashes( $content );
return $content;*/
}
protected function processMarkdownWithLatex( $content, $id ) {
$this->maybe_load_markdown();
//獲取latex代碼段
$latexSegments = $this->getLatexSegments($content);
//在markdown轉換前,替換掉latex代碼
$newContent = $content;
if($latexSegments){
$newContent = $this->replaceLatexSegments($content, $latexSegments);
}
// $content is slashed, but Markdown parser hates it precious.
$newContent = stripslashes( $newContent );
// convert to Markdown
$newContent = $this->parser->transform( $newContent );
// reference the post_id to make footnote ids unique
$newContent = preg_replace( '/fn(ref)?:/', "fn$1-$id:", $newContent );
// WordPress expects slashed data. Put needed ones back.
$newContent = addslashes( $newContent );
//將Latex代碼替換回來
$content = $newContent;
if($latexSegments){
$content = $this->recoverLatexSegments($newContent, $latexSegments);
}
return $content;
}上述框架代碼依賴的相關函數實現如下:
/**
@ 依次替換一個字符串中的多個子串, 待替換子串用位置+長度指定
*/
protected function substr_replace_multi($inputStr, $replacementArr, $startArr, $lenArr){
$retStr = "";
$lastIdx = 0;
$numReplacement = count($replacementArr);
foreach($replacementArr as $idx => $replacement){
$start = $startArr[$idx];
$len = $lenArr[$idx];
$retStr .= substr($inputStr, $lastIdx, $start - $lastIdx);
$retStr .= $replacement;
$lastIdx = $start + $len;
}
if($numReplacement > 0){
$retStr .= substr($inputStr, $startArr[$numReplacement - 1] + $lenArr[$numReplacement - 1]);
}
else if($numReplacement == 0){
$retStr = $inputStr;
}
return $retStr;
}
/**
@ 依次替換一個字符串中的多個子串
*/
protected function str_replace_multi($inputStr, $searchArr, $replacementArr){
$newReplacementArr = array();
$posArr = array();
$lenArr = array();
$offset = 0;
foreach($searchArr as $idx => $search){
$pos = strpos($inputStr, $search, $offset);
if($pos !== false){
$replacement = $replacementArr[$idx];
$newReplacementArr[] = $replacement;
$len = strlen($search);
$posArr[] = $pos;
$lenArr[] = $len;
$offset = $pos + $len;
}
}
return $this->substr_replace_multi($inputStr, $newReplacementArr, $posArr, $lenArr);
}
//正則找到所有代碼段
protected function getLatexSegments($content){
$matches = null;
//匹配雙美元符號'$$'開始和結束的代碼段。
$numMatch = preg_match_all('/(^| )\$\$(.{1,1000}?)\$\$/sm', $content, $matches, $flags = PREG_PATTERN_ORDER | PREG_OFFSET_CAPTURE);
if($numMatch){
return $matches[0];
}
return false;
}
//將latex代碼段替換為特殊字符串||@...@||
protected function replaceLatexSegments($content, $matches, $magicSeparator = "@"){
$newContent = $content;
$posArr = array();
$lenArr = array();
$replacementArr = array();
foreach($matches as $idx => $match){
$latexSegment = $match[0];
$pos = $match[1];
$len = strlen($latexSegment);
$replacement = "||".str_repeat($magicSeparator, $idx + 1)."||";
$replacementArr[] = $replacement;
$posArr[] = $pos;
$lenArr[] = $len;
}
$newContent = $this->substr_replace_multi($content, $replacementArr, $posArr, $lenArr);
return $newContent;
}
//將特殊字符串替換為latex代碼段
protected function recoverLatexSegments($content, $matches, $magicSeparator = "@"){
$searchArr = array();
$replacementArr = array();
foreach($matches as $idx => $match){
$latexSegment = $match[0];
$pos = $match[1];
$len = strlen($latexSegment);
$replacement = $latexSegment;
$search = "||".str_repeat($magicSeparator, $idx + 1)."||";
$searchArr[] = $search;
$replacementArr[] = $replacement;
}
$newContent = $this->str_replace_multi($content, $searchArr, $replacementArr);
return $newContent;
}